受到 scrapy 框架启发,本系列要实现一个异步高并发的爬虫框架,记录一下手写的过程,在 AI 横行的时代,停下来审视自己架构、高并发的基本功,我觉得是挺有意义的一件事,接下来进入正题。
1. 基础架构设计
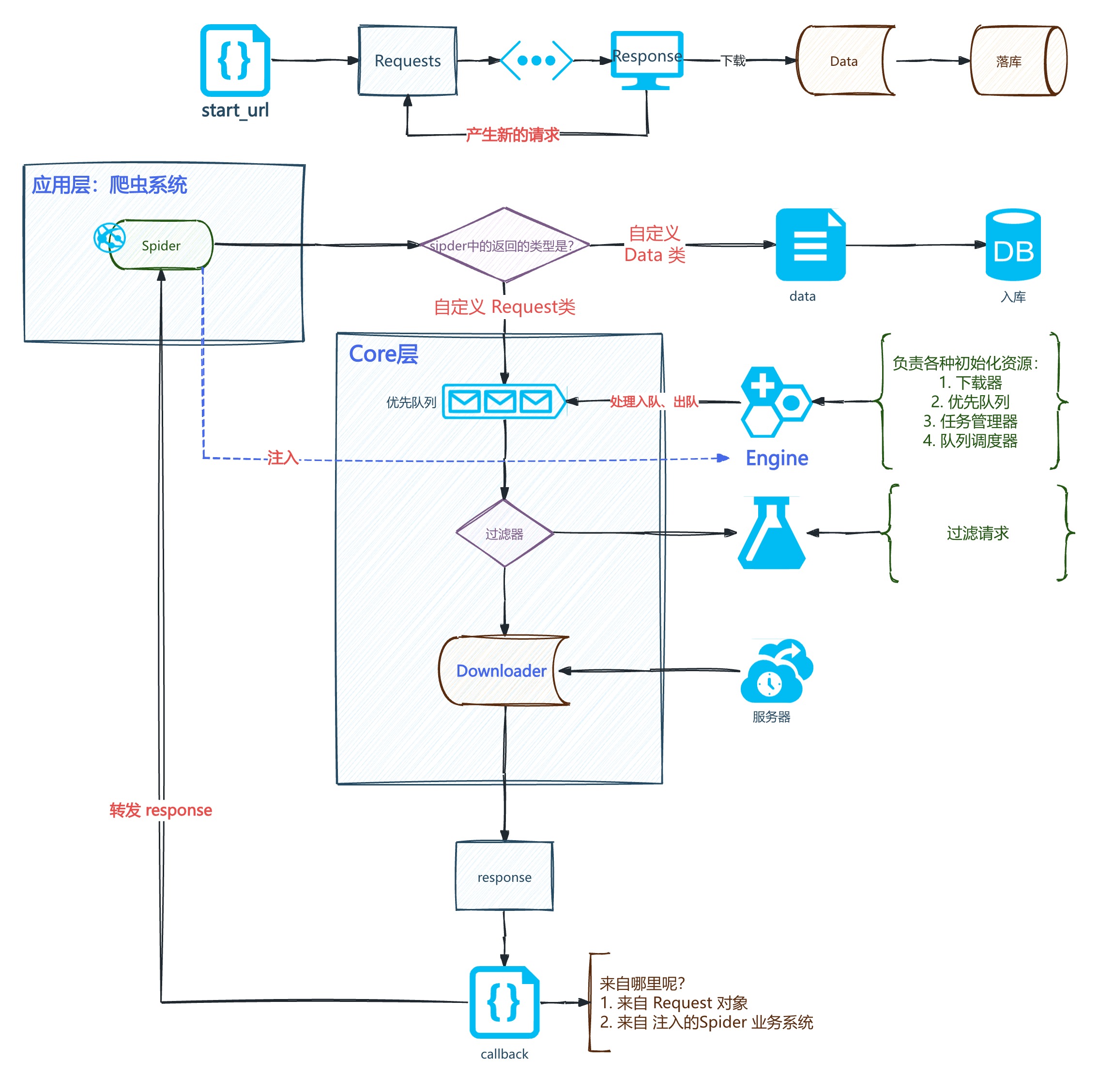
很显然,一个简单的爬虫系统就是三部分:爬虫请求、发起请求、处理响应,但是既然我们要做一个框架,它必然是高内聚、低耦合的系统,不再是单一的爬虫系统写三个部分,而是支持多个爬虫系统,也就也涉及到了:
- 多爬虫系统的调度
- 请求对象、响应对象的设计
- 下载器的设计
- 下载器如何和爬虫系统进行通信?
- 爬虫系统内部拿到响应如何处理?
- 几千几万个请求如何调度和管理,请求有没有顺序?
等等诸多问题,主要集中到:高并发、异步通信、中间件架构设计上
所以这个框架最基础的架构,必然是分层的,包括以下几个模块:
- Scheduler:调度器,负责管理请求队列和响应队列
- Downloader:下载器,负责发起请求,获取响应
- Spider:爬虫系统,负责定义爬取逻辑,处理响应
- Engine:引擎,负责协调调度器、下载器和爬虫系统的工作流程,串联起爬虫系统和下载器
的通信
- TaskManager:任务管理器,负责管理和调度大量的请求任务,控制并发度
这是最基础的部分,其他的部分后面继续补充。
所以暂时设计的架构图如下:
1.1. 架构理念
大的原则有两个:
- 高内聚、低耦合,模块之间的职责分明,互相独立
- 单一职责,关注点分离,模块之间的通信通过接口来实现,不直接依赖对方的实现细节
我觉得这在设计架构时,这两点是非常重要的,只有这样才能保证系统的可维护性、可扩展性和可测试性。
具体来说本系统的设计理念是:
- 系统的入口是一个个不同的爬虫系统,例如有个 BaiduSpider,专门爬取百度的内容,还有个 WeiboSpider,专门爬取微博的内容,这些爬虫系统都继承自一个基类 Spider,定义了爬取逻辑和处理响应的逻辑,不负责干具体的事情,例如发起请求、获取响应等,这些事情交给下载器去做,爬虫系统只负责定义爬取逻辑和处理响应的逻辑
- 下载器只负责发起请求、获取响应,不关心爬虫系统的逻辑
- 调度器负责管理请求队列和响应队列,不关心爬虫系统和下载器的逻辑
- 引擎负责协调调度器、下载器和爬虫系统的工作流程,串联起爬虫系统和下载器的通信
- 任务管理器负责管理和调度大量的请求任务,控制并发度,处理请求的优先级和重试机制,不关心爬虫系统、下载器和调度器的逻辑。
1.2. 并发编程
显而易见,爬虫系统的核心就是高并发、异步通信,所以在设计架构的时候,必须考虑到并发编程的问题,如何实现高并发、异步通信,是这个框架的核心问题之一,Python 中的协程,正好为我们提供了一个好的工具,来实现高并发、异步通信。
通过合理的封装成任务 Task 对象,来管理这些异步任务,实现高并发,也就是这部分的核心工作了。
而异步任务的统一管理,就需要抽象成一个任务管理器 TaskManager 来管理。
1.3. 任务调度器
既然我们是框架,就不再是单一的系统,来个任务就做,来个任务继续做,需要有一个更底层的抽象层来处理请求任务,所以我们先要设计好底层的数据结构,来管理这些请求任务,这就是任务队列了。
任务队列是调度器的核心组件之一,负责管理和调度大量的请求任务,控制并发度,处理请求的优先级和重试机制。设计一个高效的任务队列,是实现高并发爬虫系统的关键。
队列有很多种:先进先出(FIFO)、后进先出(LIFO)、优先级队列等,对于爬虫的请求这种任务来说,优先级队列是比较合适的,因为有些请求可能比其他请求更重要,例如首页的请求比其他页面的请求更重要,或者某些页面的请求比其他页面的请求更重要,所以优先级队列可以帮助我们更好地管理和调度这些请求任务。
所以Request 对象设计上必然有一个重要属性 priority,来表示请求的优先级,调度器在调度请求的时候,根据这个优先级来决定哪个请求先被处理。
📢: PriorityQueue 往队列中添加 Request 时,需要比较,可能有的人回想给 Request类添加一个 lt 方法来实现比较,但我觉得不太合适,因为 Request 类的核心职责是表示一个请求对象,添加比较方法会让它承担更多的职责,不符合单一职责原则
所以我觉得更好的方式是,在调度器中,统一处理排序相关逻辑,使用一个元组 (priority, request) 来存储请求,这样就可以根据 priority 来比较了。
以上三个部分是架构设计之初,都要准备好的工作,接下来我们进行简单的编码实现一下这些基础架构,后续会继续完善。
2. 基础架构编码实现
基于之前的架构设计,框架目录结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
.
├── project_tree.txt
├── README.md
├── scrax
│ ├── __init__.py
│ ├── core
│ │ ├── __init__.py
│ │ ├── decorators.py
│ │ ├── downloader.py
│ │ ├── engine.py
│ │ └── scheduler.py
│ ├── exceptions.py
│ ├── http
│ │ ├── __init__.py
│ │ └── request.py
│ ├── spider
│ │ ├── __init__.py
│ │ └── spider_base.py
│ ├── task_manager.py
│ └── utils
│ ├── __init__.py
│ ├── pqueue.py
│ └── tools.py
└── tests
├── __init__.py
├── baidu_spider
│ ├── __init__.py
│ ├── baidu.py
│ └── run.py
9 directories, 26 files
|
2.0 应用层设计
先看应用层,爬虫系统的代码,这里是入口:
1
2
3
4
5
6
7
8
9
10
|
from scrax import SpiderBase
from scrax.http import Request
class BaiduSpider(SpiderBase):
start_urls = ['https://www.baidu.com', 'https://www.baidu.com']
def start_requests(self):
# 业务类不需要做具体的事情,只暴露下载的 URL 即可
return [Request(url=url) for url in self.start_urls]
|
为什么我们要设计一个基类呢,是为了统一一些爬虫系统的操作,例如:
- 都要实现 start_requests 方法,来暴露下载的 URL,这样就可以在引擎中统一调用了,不需要关心具体的爬虫系统的实现细节了。
- 都要实现 parse 方法,来处理响应
2.1. http模块
2.1.1. Request 和 Response 对象设计
代码初期 Request 和 Response 对象比较简单,就是将请求的 URL、请求方法、请求头、请求体等信息封装成一个 Request 对象,响应的状态码、响应头、响应体等信息封装成一个 Response 对象,这样就可以更好地管理和处理这些请求和响应了。
后续随着代码的深入,会继续完善。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
"""HTTP请求"""
from collections.abc import Callable
class Request:
def __init__(
self,
url,
callback: Callable = None,
priority: int = 0,
headers: dict | None = None,
cookies: dict | None = None,
):
self.url = url
self.callback = callback
self.priority = priority
self.headers = headers
self.cookies = cookies
"""响应"""
class Response:
def __init__(self, *, url=None, status_code=None, headers=None, content=None):
self.url: str|None = url
self.status_code: str|None = status_code
self.headers: dict|None = headers
self.content: str|None|dict = content
|
2.2. core模块
core 模块是整个框架的核心模块,包含了调度器、下载器、引擎等核心组件的实现,这些组件是整个框架的基础,其他组件都是基于这些核心组件来实现的,所以 core 模块的设计和实现是非常重要的。
2.2.1. Scheduler的设计
Scheduler 的核心组件之一就是任务队列了,前面我们已经提到过了,要用优先级队列,我们姑且先用 Python 自带的Priority 进行处理,这里埋个 伏笔 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
"""
任务调度器
把 Request组成的元组 加入到优先队列中,元组可以天然的按照字典序 ,从第一个位置比较顺序
(Request.priority, count, Request)
"""
import asyncio
from asyncio import PriorityQueue
from itertools import count # 生成唯一id
from crawlix.http import Request
class Scheduler:
def __init__(self):
# 类型注解,延迟初始化
self.queue: PriorityQueue | None = None
self._counter = count()
def open(self):
# 真正的初始化
self.queue = PriorityQueue()
async def next_request(self):
return await self.queue.get()
async def enqueue_request(self, request: Request):
# 入队,生产
queue_item = (request.priority, next(self._counter), request)
await self.queue.put(queue_item)
|
2.2.2. downloader 的设计
Downloader 的核心职责就是发起请求,获取响应,不关心爬虫系统的逻辑,所以它初期设计相对来说比较简单,主要是封装一些 HTTP 请求库.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import asyncio
from scrax.http import Request
import requests
class Downloader:
def __init__(self):
# 暂时还不需要什么属性,后续再完善
async def fetch(self, request: Request):
"""返回响应内容"""
result = await self.download(request)
async def download(self, request: Request):
"""
下载器的核心功能:下载请求
:param request: 请求对象
:return:
"""
# 下载器的核心功能:下载请求
# response = requests.get(request.url)
# print(response)
# 假数据模拟
await asyncio.sleep(random.random()) # 随机数 [0.0, 1.0)
return 'result'
|
2.2.3. Engine 的设计
Engine 的核心职责就是协调调度器、下载器和爬虫系统的工作
他前期就是要是初始化调度器和下载器,然后执行爬取的流程,期待的使用方式是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 具体的爬虫业务系统的启动入口
# /scrax/tests/baidu_spider/run.py
import asyncio
import time
from baidu import BaiduSpider
from scrax.core.engine import Engine
async def run():
baidu_spider = BaiduSpider()
engine = Engine()
await engine.start_spider(baidu_spider)
if __name__ == '__main__':
start_time = time.perf_counter()
asyncio.run(run())
end_time = time.perf_counter()
print(f'爬虫运行时间: {end_time - start_time} 秒')
|
希望通过 engine 来启动框架,接收不同的爬虫应用,基于这个设计,如下实现 Engine 类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
"""引擎"""
# engine.py
from scrax.core.downloader import Downloader
from scrax.core.scheduler import Scheduler
class Engine:
def __init__(self):
# 类型注解实现变量声明,延迟初始化
self.downloader: Downloader | None = None
self.spider: SpiderBase | None = None
self.start_requests: Iterator[Request] | None = None
self.is_running = False # 控制爬取
self.scheduler: Scheduler | None = None
async def start_spider(self, spider: SpiderBase):
self.is_running = True # 开始爬取
self.scheduler = Scheduler()
if hasattr(self.scheduler, 'open'):
self.scheduler.open()
else:
raise RuntimeError('Scheduler does not have open method!!!')
self.spider = spider
self.start_requests = iter(spider.start_requests()) ✅ 关注点 1# 兼容处理,统一成迭代器
self.downloader = Downloader()
# 执行爬取
await self.crawl()
async def crawl(self):
# 爬取流程
pass
|
注意上面的关注点 1:我们在引擎中调用爬虫系统的 start_requests 方法,来获取初始请求,这个方法可能返回一个列表,也可能返回一个生成器,所以我们统一将它转换成一个迭代器,进行归一化处理。
这里再稍微停顿一下,第一版快速实现时,是如上写的,但是仔细一想,如果执行 crawl 很久,我下面想做其他事情,就被crawl阻塞了,所以应该将它单独封装成一个异步任务,在支线执行,不影响主任务流程,等待合适时机,支线任务完成后,通知主任务即可,所以上面代码优化成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# engine.py
async def start_spider(self, spider: SpiderBase):
self.is_running = True # 开始爬取
self.scheduler = Scheduler()
if hasattr(self.scheduler, 'open'):
self.scheduler.open()
else:
raise RuntimeError('Scheduler does not have open method!!!')
self.spider = spider
self.start_requests = iter(spider.start_requests()) # 兼容处理,统一成迭代器
self.downloader = Downloader()
# 执行爬取
# await self.crawl() # 这里的逻辑也有抽离出去做支线任务,因为万一下面有操作会被阻塞
await self._open_spider()
async def _open_spider(self):
crawling = asyncio.create_task(self.crawl()) # 交给支线任务,不耽误主任务执行
# 这里可以做其他事情
await crawling
|
这样操作的话,其他操作也有了空间,然后异步任务交给了 crawling 变量来管理,等待它完成后,继续执行下面的逻辑。
接下来我们重点分析一下 crawl 函数的设计,他的作用就是爬取主逻辑,之所以抽象这一层, 就是为了分离职责,不在引擎内直接处理请求,只是通过调度器的管理。
实现上:开启一个循环获取请求,发起请求,交给下载器处理,处理完响应后继续获取下一个请求,直到没有请求了,爬取结束。
本质是将请求入队(生成)、出队(消费)、下载、处理响应的流程串联起来,形成一个完整的爬取流程。
基于生产者消费者模型,最好是先消费后生产,防止挤压过多请求到队列中,导致内存占用过高,同时也能更好地控制爬取的节奏和并发度。
注意📢:
Engine 内 crawl爬取逻辑需要:while循环获取,而不是判断固定长度,因为并发时有多个任务在运行
- 队列可能暂时为空,但任务正在处理中
- 处理中的任务可能会生成新请求,继续入队
- 需要等待所有任务完成才能退出
只有 while 不断循环,才能确保不会遗漏任务
这里的 while 循环固然可以使用死循环,配合 break 来控制退出,但我更好的方式是使用一个控制变量 is_running 来控制循环的执行、退出,这样代码更清晰。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# engine.py
async def crawl(self):
"""爬取主逻辑"""
while self.is_running:
# 循环爬取,只要任务队列中有数据
# 1. 先消费,出队
request = await self._get_next_request() # ✅关注点 4
if request is not None:
# 有数据
# 执行真正的爬
await self._crawl(request) # ✅ 关注点 3
else:
# 没数据:就先从初始请求队列中,去请求入队,
# 下次再进循环,就能取到请求 -> 可正常爬取了,这次请求中间遇到请求再入队
if self.start_requests is not None:
try:
# 从初始请求中拿一个,这个请求入队,不直接执行
start_request = next(self.start_requests)
except StopIteration:
# 初始请求队列取完了 ✅关注点2
self.start_requests = None
else:
# 初始请求入队,生产 ✅关注点1
await self.enqueue_request(start_request)
else:
# 能到这说明:队列中也没有数据了,初始请求也耗尽了,就退出主逻辑
self.is_running = False
|
这个函数很简单吧,其中有3个关注点要分离,先看:
- 关注点 1: 入队操作,要单独拆分一层,进行解耦,这样设计为了预留去重的空间,如果直接在 crawl 函数中入队,那么后续添加去重逻辑就比较麻烦了,所以我们单独拆分一层来处理入队的逻辑。
1
2
3
4
5
6
7
8
9
|
# engine.py
async def enqueue_request(self, request: Request):
# 继续拆分函数,这里只处理入队,至于入队之前的各种预处理,交给其他函数来处理
# 这样职责分离,代码更清晰
await self._schedule_request(request)
async def _schedule_request(self, request: Request):
# TODO 真正入队前会有去重逻辑
await self.scheduler.enqueue_request(request)
|
1
2
3
|
async def _get_next_request(self):
# 出队
return await self.scheduler.next_request()
|
还记得我们之前的伏笔 1 吗?,我们出队用的自带的优先队列的 get(),现在会遇到一个大问题
隐藏的bug
当你用了原生优先队列的 get() 方法时,它会一直等待队列中有数据,而入队操作要等到取不到request 才能执行,这就导致了卡死:当队列中没有数据时,get() 会一直等待,而入队操作又需要等到 get() 取不到数据才会执行,这样就形成了一个死循环,导致程序无法继续执行下去。
而 get()方法没有天然的超时操作,怎么办呢?
这个方法不要直接 await,执行get 方法会返回一个协程对象,这样就可以使用 asyncio.wait_for 来给 get() 方法添加一个超时操作,这样当队列中没有数据时,get() 会在超时时间到达后抛出一个 asyncio.TimeoutError 异常,我们就可以捕获这个异常来处理没有数据的情况了。
所以我们可以重写一个优先队列,重写 get方法,使其具备超时操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import asyncio
from asyncio import PriorityQueue
from asyncio.exceptions import TimeoutError
from crawlix.http import Request
class SpiderPriorityQueue(PriorityQueue):
def __init__(self, maxsize=0):
super().__init__(maxsize)
async def get(self) -> tuple[int, int, Request]|None:
# 出队 消费
get_coro = super().get() # 不能直接 await,等不到数据会卡死,所以先获取到 协程对象,再操作超时
try:
queue_item = await asyncio.wait_for(get_coro, timeout=0.1)
return queue_item
except TimeoutError:
return None
|
再把调度器中的队列换成自定义的SpiderPriorityQueue,当队列中没有数据时,返回 None,crawl 函数就知道此时队列为空,去处理初始请求了,进而入队。
下次循环进来就有了请求,如果这个请求又发起了新的请求,他会继续入队,一直优先被消费掉。
这个逻辑怎么实现呢?
就在:
- 关注点 3,实现_crawl函数,处理请求,把响应拿到,交给回调函数处理,回调可能来自于请求或者爬虫系统,按照约定爬虫的默认回调应该是 parse,如下是爬虫系统的示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# baidu_spider.py
from crawlix.http import Request
from crawlix.spider.spider_base import SpiderBase
class BaiduSpider(SpiderBase):
start_urls = ['https://www.baidu.com', 'https://www.baidu.com']
def __init__(self):
super().__init__()
def parse(self, response):
print(f'parse {response}')
# 这里可能又会产生新的请求,注意,这里如果再产生,一定要有自定义的 callback,重新分发到其他的回调上
# 不然会一直进入parse 一直重复
for i in range(10):
url = f'https://www.baidu.com?page={i}'
request = Request(url=url, callback=self.parse_page)
yield request
async def parse_page(self, response):
print(f'parse page {response}')
for i in range(10):
url = f'https://www.baidu.com?page={i}'
request = Request(url=url, callback=self.parse_detail)
yield request
def parse_detail(self, response):
print(f'parse detail {response}')
|
按照约定,爬虫系统的返回应该只有三种类型:1. 协程 2. 异步生成器 3. 生成器,所以我们在引擎中处理回调函数的返回值时,需要对这三种类型进行兼容处理,统一转换成异步生成器,这样就可以在 _handle_spider_output 函数中,统一使用 async for 来处理了。
为什么我们要返回生成器呢?直接遍历返回列表不是更简单吗?
因为生成器有以下优势:
- 内存高效: 惰性求值,按需生成 Request 对象,避免一次性创建大量对象只有在遍历时候才会生成下一个值,不遍历函数就不会执行,
- 延迟计算: 只有在需要下一个请求时才执行生成逻辑
- 流式处理: 支持处理大量 URL 而不会内存溢出
- 可暂停执行: 生成器可在 yield 处暂停,保持执行状态
这样就可以更好地控制爬取的节奏和并发度了,如果直接返回列表,那么就会一次性生成所有的请求,可能会导致内存占用过高,或者爬取过快被目标网站封禁了,所以使用生成器可以更好地控制爬取的节奏和并发度了。
所以实现_crawl 函数的核心逻辑就是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
async def _crawl(self, request):
# 真正执行爬的
outputs = await self._fetch(request)
if outputs:
# 1. 应该单独处理 outputs
await self._handle_spider_output(outputs) # ✅ 关注点 3
async def _fetch(self, request: Request):
_response = await self.downloader.fetch(request) # 有成功 、失败,暂定都成功了
# 拿到响应后,应该交给爬虫系统去处理,也就是交给回调函数即可
# 拿到的回调结果需要重新交给_crawl处理,看看是什么类型,如果新的请求需要重新入队
async def _success(response):
callback = request.callback or self.spider.parse
if callback:
outputs = callback(response)
if outputs:
# 只可能是 1. 协程 2. 异步生成器 3. 生成器
if iscoroutine(outputs):
await outputs
return None
else:
# 需要转换一下
return transform(outputs) # ✅ 关注点 2
else:
# 没有返回的话,直接直接完,返回 None 即可
return None
else:
raise RuntimeError('callback must not be None')
return await _success(_response)
|
注意上面的 两个关注点:
- 关注点 2,经过前面的判断,协程对象单独处理,剩的就是异步生成器和生成器,这里统一成异步生成器
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from inspect import isasyncgen, isgenerator
from crawlix.exceptions import TransformTypeError
async def transform(outputs):
if isgenerator(outputs):
# 普通生成器
for fun_result in outputs:
yield fun_result
elif isasyncgen(outputs):
async for fun_result in outputs:
yield fun_result
else:
raise TransformTypeError('callback return values must be `generator` or `async generator`')
|
统一成异步生成器之后,我们就能实现
1
2
3
4
5
6
7
8
|
async def _handle_spider_output(self, outputs):
async for spider_out in outputs:
# 如果是请求,继续入队,如果不是抛出错误
if isinstance(spider_out, Request):
await self.enqueue_request(spider_out)
# 后续完善是数据类型的处理
else:
raise OutputError('output must be Request')
|
遍历异步生成器,判断返回值是不是 Request:
- 如果是Request就入队
- 如果不是就抛出错误
- 后续我们也可以在这里添加其他类型的处理,例如 Item 对象等。
至此,我们完成了架构的大部分,此时最大的问题问题,都是阻塞的单步执行,没有实现高并发,接下来要实现并发请求
3. 并发核心实现
核心的爬取逻辑在_crawl函数中,目前是一个一个执行的,想要实现高并发,我们需要将这个函数改造成一个异步任务,让它能够同时处理多个请求,这样就能实现高并发了。
实现上,可以使用 asyncio.create_task 包装内部逻辑成一个异步任务:
1
2
3
4
5
6
7
8
9
10
|
async def _crawl(self, request):
async def crawl_task():
# 真正执行爬的
outputs = await self._fetch(request)
if outputs:
# 1. 应该单独处理 outputs
await self._handle_spider_output(outputs)
# 循环一次生成一个任务
self.task_manager.create_task(crawl_task())
|
改写完之后:
- 每循环一次,生成一个异步任务,异步任务在支线去执行,而不是每次要执行玩一个请求再执行下一个。
- 异步任务的完成结果通过 done 通知 future
现在异步操作有了,接下来要考虑的就是并发度了,过高可能会被目标网站封禁,过低又达不到爬取的效率,所以我们需要一个机制来控制并发度,这个机制就是任务管理器了,任务管理器负责管理和调度大量的请求任务,控制并发度,处理请求的优先级和重试机制等。
实现上使用 semaphore 信号进行控制并发
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
from asyncio import Semaphore, Task
import asyncio
class TaskManager:
def __init__(self, max_concurrency: int = 10):
self._semaphore: Semaphore = Semaphore(max_concurrency) # 任务最大并发量
self._active_tasks = set()
self._max_concurrency = max_concurrency
@property
def semaphore(self):
return self._semaphore
@property
def max_concurrency(self):
return self._max_concurrency
@property
def active_task_count(self):
return len(self._active_tasks)
def create_task(self, coro):
task = asyncio.create_task(coro)
self._active_tasks.add(task)
def _task_done(_: Task):
# 完成任务后移除任务,静默移除,防止中断后续任务
self._active_tasks.discard(task) # ✅ 关注点 2
# 如果任务完成回调中发生错误,静默处理
try:
_.exception()
except asyncio.CancelledError:
pass # ✅ 关注点 1
# 任务完成后,释放信号量
self._semaphore.release()
task.add_done_callback(_task_done) # 设置回调处理完成后的逻辑
return task
def all_done(self):
return len(self._active_tasks) == 0
|
注意上面的两个关注点,在大量爬虫过程中,有个基本原则:不希望某个请求出问题中断主任务的执行,所以:
- 关注点 2: 一开始移除元素可能会想到用集合的 remove 方法,但是remove会在元素不在时,报 KeyError的错误,而discard 同样会移除,但是如果找不到就不做处理
- 关注点 1: 对于任务完成的过程中报错,抓取后暂时静默处理
至此,基础架构+并发执行,初步完成,但是仔细看看目前的实现,发现有两个大问题:
3.1. 退出主循环的标志
没有用并发时,之前我们退出主循环,只是简单判断任务队列没数据+初始请求消耗完,就退出了,但是如果下载任务中还有正在下载的、调度器的队列中还有未入队的请求,此时提前退出的话,相当于遗漏了任务。
所以,退出主循环的逻辑要严格:
1
2
3
4
5
6
7
|
# engine.py
def should_exit(self) -> bool:
# 是否应该退出主循环
if self.task_manager.all_done() and self.downloader.is_idle() and self.scheduler.is_idle():
return True
return False
|
主逻辑的退出条件用这个校验方法,判断
1
2
|
if self.should_exit():
self.is_running = False
|
- 修改下载器逻辑,增加空闲函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
"""处理下载响应"""
import asyncio
import random
import requests
from crawlix.http import Request, Response
class Downloader:
def __init__(self):
# 初始化,当前下载的任务集合
self._downloads = set()
async def fetch(self, request: Request):
self._downloads.add(request)
response = await self.download(request)
# 获取完结果后,移除
try:
self._downloads.remove(request)
except KeyError:
raise RuntimeError('remove request KeyError')
return response
async def download(self, request: Request) -> Response | str |None:
await asyncio.sleep(random.random()) # 模拟异步网络请求
return 'download result'
def is_idle(self):
return len(self._downloads) == 0
|
- 修改调度器逻辑,增加空闲函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
"""
任务调度器
把 Request组成的元组 加入到优先队列中,元组可以天然的按照字典序 ,从第一个位置比较顺序
(Request.priority, count, Request)
"""
import asyncio
from crawlix.utils.pqueue import SpiderPriorityQueue # 使用优先队列
from itertools import count # 生成唯一id
from crawlix.http import Request
class Scheduler:
def __init__(self):
# 类型注解,延迟初始化
self.queue: SpiderPriorityQueue | None = None
self._counter = count()
def open(self):
# 真正的初始化
self.queue = SpiderPriorityQueue()
async def next_request(self):
# # 出队 消费
queue_item = await self.queue.get()
if queue_item:
_, _, request = queue_item
return request
else:
return None
async def enqueue_request(self, request: Request):
# 入队,生产
queue_item = (request.priority, next(self._counter), request)
await self.queue.put(queue_item)
def __len__(self):
return self.queue.qsize()
def is_idle(self):
return len(self) == 0
|
3.2.1. 精细的并发控制
仔细看一下之前的并发逻辑,现在是一个一个的打到队列中,虽然是同时有多个任务并发执行,但是并发的槽位,没有被打满,浪费。
需要继续优化: