0. 为什么要版本控制
进行后端开发时,数据库的表结构可能会变化。
如果此时已经有一些数据了,你可能为了避免丢失测试数据,会手动修改表结构,或者进行一些手动操作。
又或者一开始你写 model层时,手误了,写错了字段名字,改完了代码,还得去对应的改表结构。

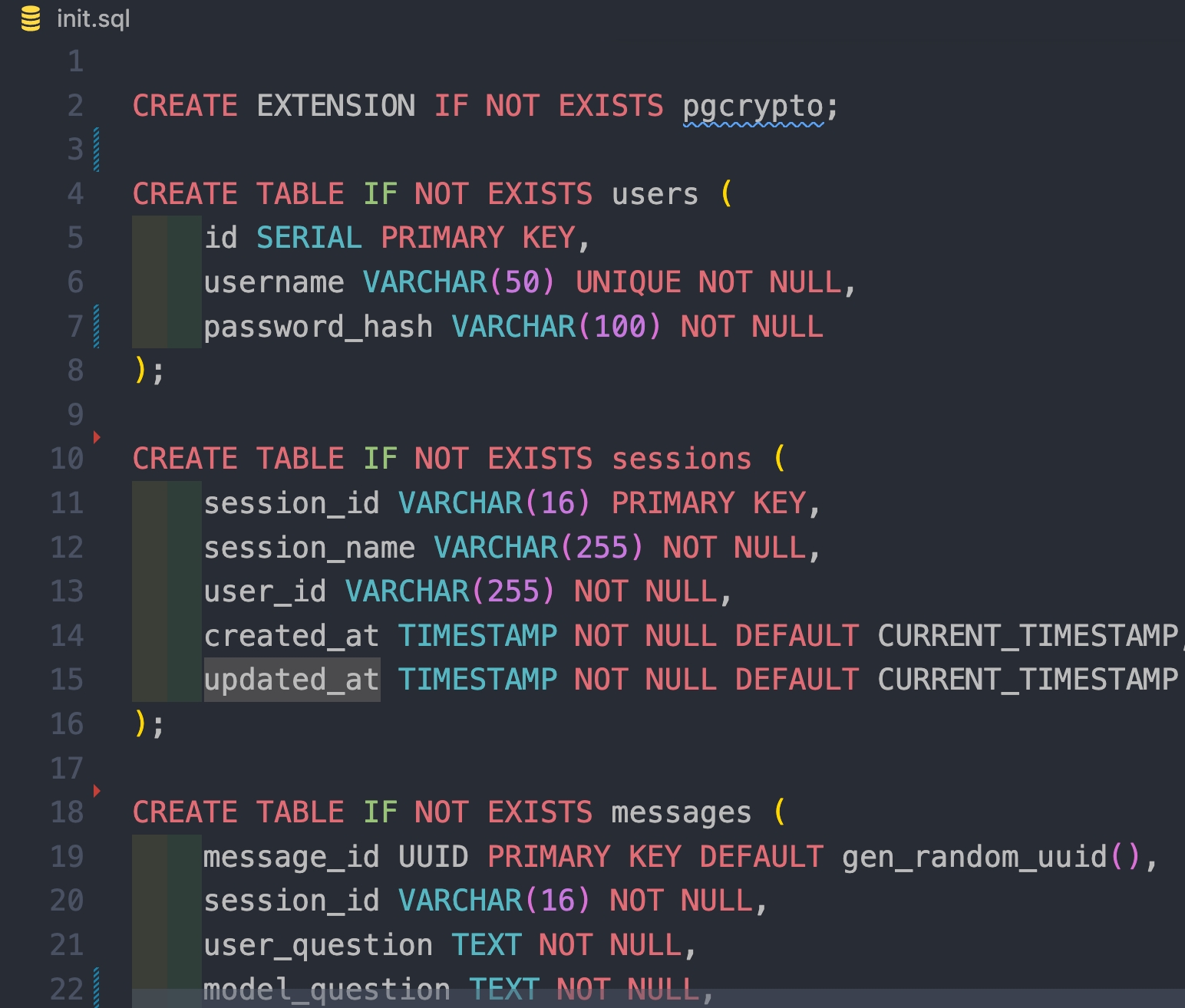
以上这两种情况,手动去改都难免会有问题,可能就会有脏数据、字段对应不上报错等等奇怪问题。
这就涉及到了对数据库结构(Schema)的每一次变更进行版本管理,最好能像 git一样,有不同的 version 进行追踪。
基于我们的后端现状,python 开发+docker 部署,SQLAlchemy 做 ORM 框架,可以使用Alembic进行数据库版本管理和迁移工作。
1.1 初始化项目
- 通过
alembic init <directory_name>,这个命令在当前目录下创建一个名为 <directory_name> 的迁移环境,同时还会在外层包含配置文件 alembic.ini。
一般创建后的目录结构如图
1
2
3
4
5
6
|
.
├── __pycache__
├── env.py
├── README
├── script.py.mako
└── versions
|
其中 versions 目录存放版本,env.py控制数据源环境,一般只需要修改数据源配置即可:
1
2
3
4
5
6
7
8
9
10
|
# !!!add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
from models import Base
target_metadata = Base.metadata
|
将你的 model 层目录导入,作为目标源。
- 修改 alembic.ini的脚本位置为你刚才生成的目录,例如我刚刚放到了alembic目录下,那么:
1
2
3
4
5
6
7
8
|
# alembic.ini 开头修改脚本位置,其他不用动
# A generic, single database configuration.
[alembic]
# path to migration scripts
script_location = %(here)s/alembic
|
- 在Docker 模式下,生成迁移脚本:
1
|
docker compose exec xxx_后端服务API bash -lc "cd /app && alembic revision --autogenerate -m 'initial schema'"
|
- 执行迁移并查看当前版本:
1
|
docker compose exec xxx_后端服务API bash -lc "cd /app && alembic upgrade head && alembic current -v"
|
2.1 标准流程
有了管理数据表的最佳实践,就要形成一个标准流程:
- 第一次docker启动时:
- 在dockerfile中的start.sh 执行 alembic stamp baseline
- start.sh 执行 alembic upgrade head
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
# 这是 start.sh中比较重要的一段
# 检查并运行数据库迁移
echo "检查数据库迁移状态..."
python -c "
import os
from alembic.config import Config
from alembic import command
from alembic.script import ScriptDirectory
from alembic.runtime.environment import EnvironmentContext
from sqlalchemy import create_engine, text
try:
# 检查是否存在alembic_version表
alembic_cfg = Config('alembic.ini')
engine = create_engine(os.environ['DATABASE_URL'])
with engine.connect() as conn:
result = conn.execute(text(\"SELECT EXISTS (SELECT FROM information_schema.tables WHERE table_name = 'alembic_version')\"))
table_exists = result.scalar()
if not table_exists:
print('首次部署,标记baseline...')
command.stamp(alembic_cfg, '980b32f130df')
print('Baseline标记完成')
print('运行数据库迁移...')
command.upgrade(alembic_cfg, 'head')
print('数据库迁移完成!')
except Exception as e:
print(f'迁移过程出错: {e}')
# 不退出,继续启动应用(向下兼容)
print('警告: 迁移失败,但应用将继续启动')
"
|
- 后续改表:
- 修改 models
- 生成 migration
- 执行 alembic upgrade head
- 数据库表结构同步更新
例如你修改了某个表字段,会在 versions 中增加记录
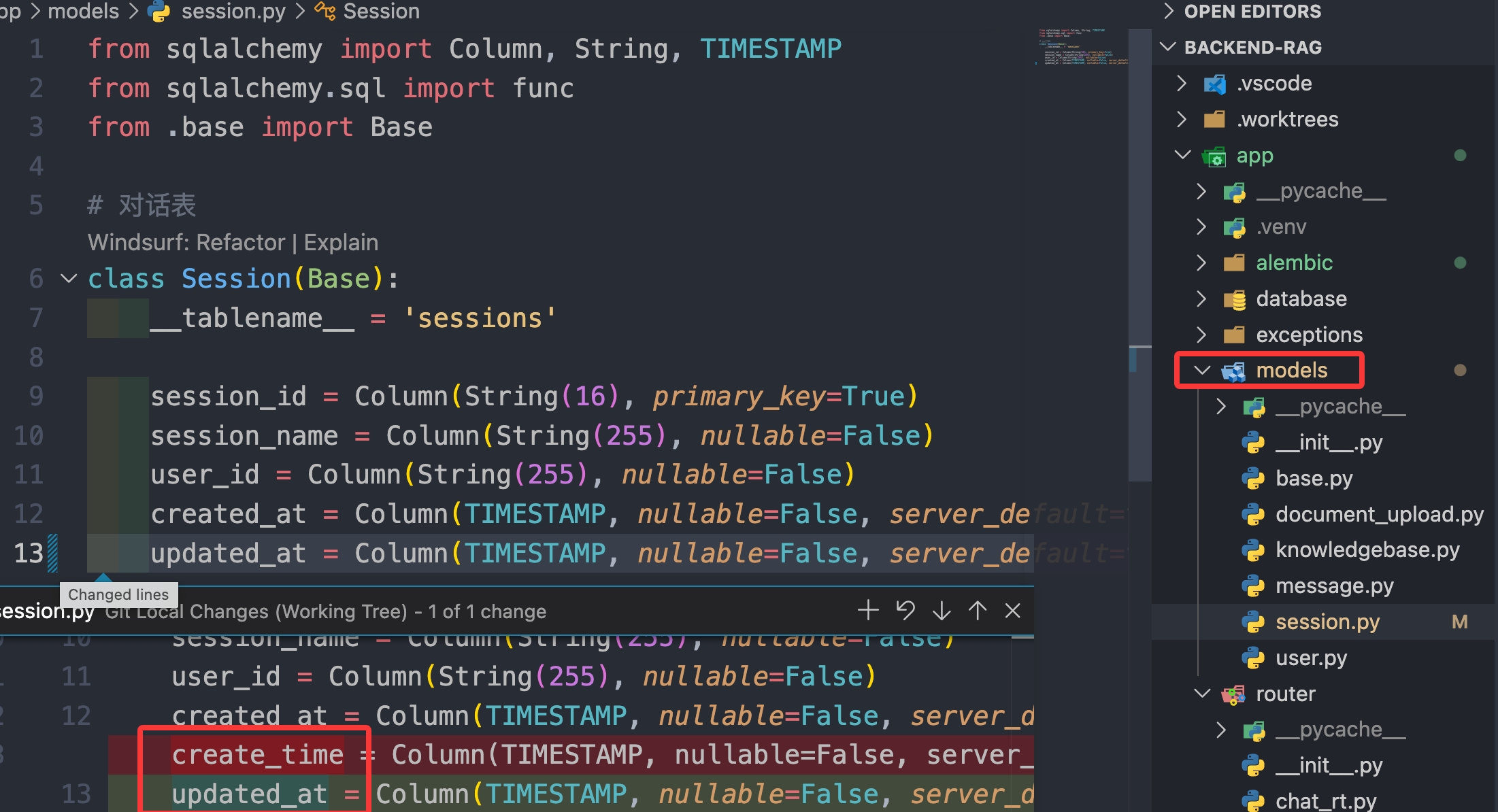
2.1.1 拆解标准流程
每当你你改了 models/*.py,流程必须是:
1
|
docker compose exec xxx_后端服务API sh -c "cd /app/app && alembic revision --autogenerate -m '描述这次表结构变更'"
|
这会在这里生成新文件:
1
|
app/alembic/versions/xxx_后端服务APIx_描述这次表结构变更.py
|
然后你要打开这个文件检查一下,确认 Alembic 生成的 upgrade() 是你想要的,比如:
1
2
3
|
op.add_column(...)
op.drop_column(...)
op.create_index(...)
|
例如我发现字段写错了,改成 updated_at了,检查时,hash 值一样,更新字段的操作符合预期才行。
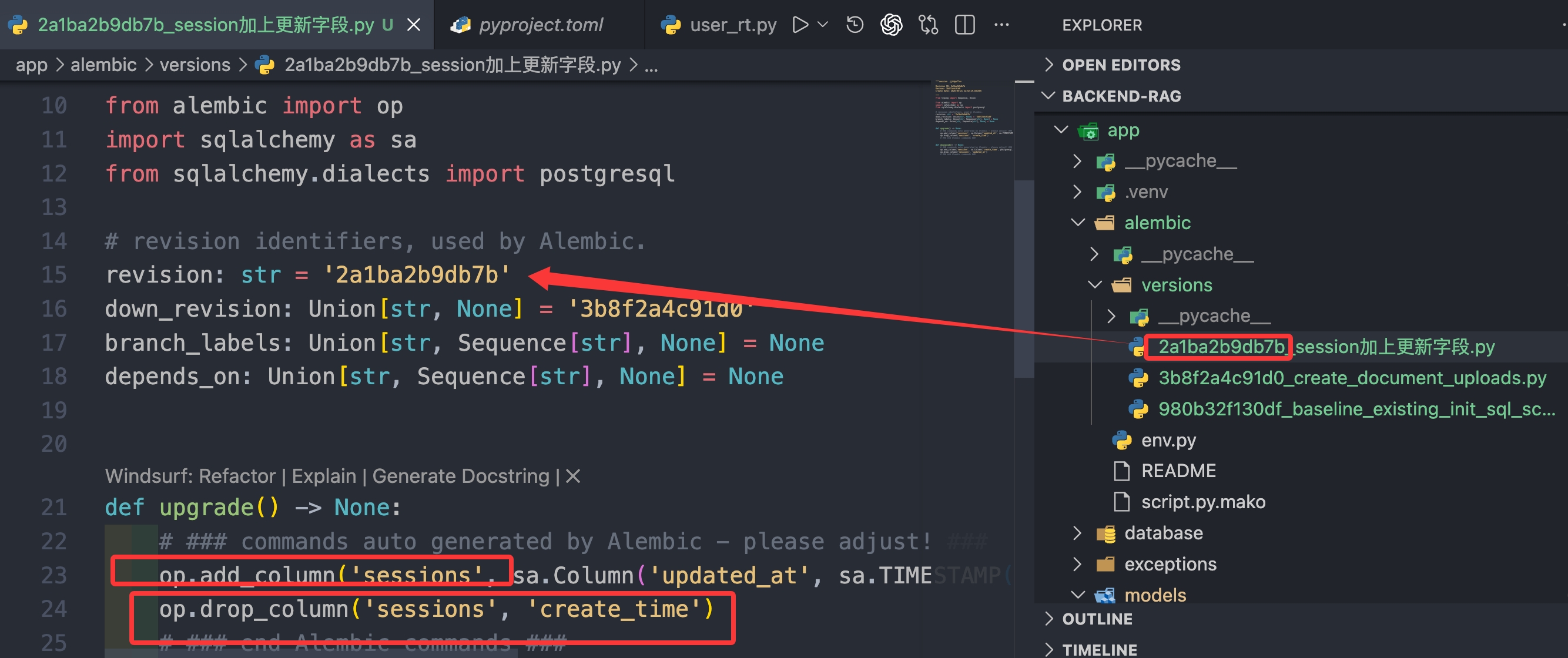
确认没问题后执行:
1
|
docker compose exec xxx_后端服务API sh -c "cd /app/app && alembic upgrade head"
|
以后服务启动时,start.sh 里的:
1
|
command.upgrade(alembic_cfg, 'head')
|
也会自动把数据库升级到最新版本。
3.1 总结
一句话:
1
2
3
4
|
models 改结构
=> alembic revision --autogenerate
=> 检查 migration
=> alembic upgrade head
|
init.sql 只负责新数据库表的初始化,不负责后续表结构演进。alembic 负责表结构更新