本文的主题是“分词器”,乍一看是不是感觉很陌生,其实我如果不做 RAG系统开发,我也是懵逼🙂↕️,幸好经过调试、开发了我们游戏内的自定义分词器后,现在熟了一些,本文涉及的项目内容、架构实现,都已经经过精简、脱敏处理,仅做📝
1. 什么是分词器
简而言之,分词器的主要任务是将文本分割成有意义的单词或短语,以便于计算机理解和处理。分词器在许多NLP任务中都有广泛的应用,比如文本分类、情感分析、机器翻译等。
而在RAG系统的几个核心模块中:
- 文档切块
- embedding
- 检索
- rerank
- prompt 拼接
- LLM 回答
- 引用回传
很显然,检索模块很重要,查不到、查不准东西,这系统还有个屁用呀……其中分词器,就是检索模块的优化点之一!!!
有人会说,现在都是 LLM的时代了,直接用向量索引、相似度计算,我只需要向量索引就挺好啊,分词器好像没什么用了呀:
1
2
3
|
用户问题 -> embedding
文档 chunk -> embedding
向量相似度召回
|
但是在特定领域内,例如俺们的游戏场景下,很多特定名词、游戏术语,尤其是中文天然没有空格,例如用户问:“战士20级七杀阵和坐骑捕获培养怎么做?”,向量根据相似度计算容易把诛仙阵、坐骑合成都给你搞回来,而如果能用全文检索,就直击命门:
1
2
3
4
|
战士
20级
七杀阵
坐骑捕获培养
|
虽然你不用分词,向量查询也能做,但结果没有那么精准,尤其我们的游戏领域场景,大量的专有名词:
1
2
3
4
5
6
7
8
|
七杀阵
阪泉擂台赛
坐骑捕获培养
血盟据点战
弑神进阶
幻魔宫
万劫窟
装备易魂
|
所以啊,检索必然是混合检索模式:
1
2
3
4
5
6
|
query
-> 分词全文检索 content_ltks/content_sm_ltks
-> embedding 向量检索 q_1024_vec
-> 合并召回
-> rerank
-> LLM 生成答案
|
这也是为什么分词越来越重要的原因了,如果你用 ES 做全文检索,非常依赖content_ltks/content_sm_ltks,一个粗粒度内容、一个细粒度内容,而这两个字段,就是通过分词器生成的。
我们目前的做法就是原文 chunk会同时包含多部分:
1
2
3
4
5
6
|
{
"content_with_weight": "战士20级七杀阵和坐骑捕获培养怎么做?",
"content_ltks": "战士 20级七杀阵 和 坐骑捕获培养 怎么 做",
"content_sm_ltks": "战士 20级 七杀阵 七杀 杀阵 和 坐骑 骑捕 捕获 获培 培养 怎么 做",
"q_1024_vec": [0.01, 0.23, ...]
}
|
而中文又没有空格,程序不知道一句话到底啥意思,如何更好的分词呢?接下来进入正文
1.1 朴素的分词器
最常见的库,就是 jieba 了,他的分词原理不学 NLP 的话,大概了解一下就行:他内部有一个巨大的词典,包含词和词频,类似于:
1
2
3
4
5
|
数据分析 词频
项目经理 词频
Python 词频
后端 词频
开发 词频
|
他从第一个汉字开始查词典,它会把所有可能切法组成一个 DAG,有向无环图。然后从 DAG 中找到权重最大的路径,就是分词结果。例如:
1
2
3
|
数据 / 分析 / 项目 / 经理
数据分析 / 项目经理
数据 / 分析项目 / 经理
|
如果遇到没有的词时,怎么办呢?默认会用隐式马尔科夫链HMM 模型通过概率预测寻找,研究生的随机过程专业课又来攻击我了😭,总之就是这样。
所以当我们
1
2
3
|
import jieba
print(jieba.lcut("南京市长江大桥"))
|
结果通常是:['南京市', '长江大桥'],而不是会[‘南京’, ‘市长’, ‘江大桥’],因为词典中前面那条路径权重更大。
回到我们的游戏场景:
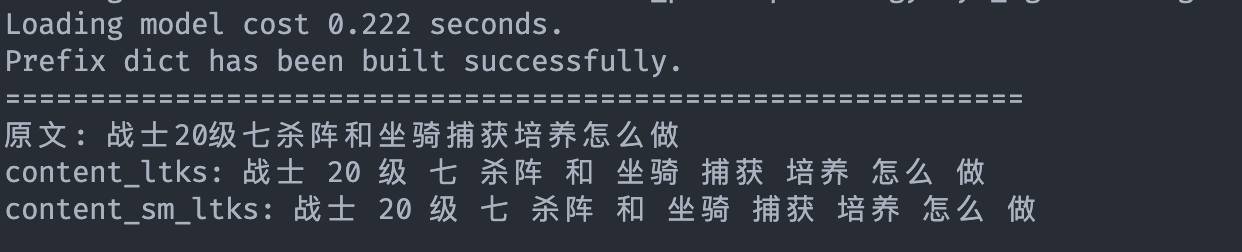
很明显,“战士20级七杀阵和坐骑捕获培养怎么做”,我们期望“20 级”、“七杀阵”是完整名词,不能分开,仅仅靠简单的第三方库无法高命中率,何况我们那么多游戏专业名词,他根本就分不出来。 最起码我们要做到:

这也能看出来分词的目标:尽可能偏完整的词、拆出更多召回的词
要做到这一点,我们面临几个问题:
- 可能需要自定义字典
- 字典来源是什么
- 如何构建字典
- 中英文混杂的问题中,技术词、英文、数字是否稳定?
- 构建字典后,如何评估这套分词合格
- 等等
总之,分词没有唯一标准,关键看“检索是否更容易命中、RAG 能不能召回正确 chunk”。
这些问题我们一个一个的来解决:
1.2 自定义字典
所谓的自定义字典,就是一个 txt 或者 trie树,里面包含所有我们需要的词,例如:
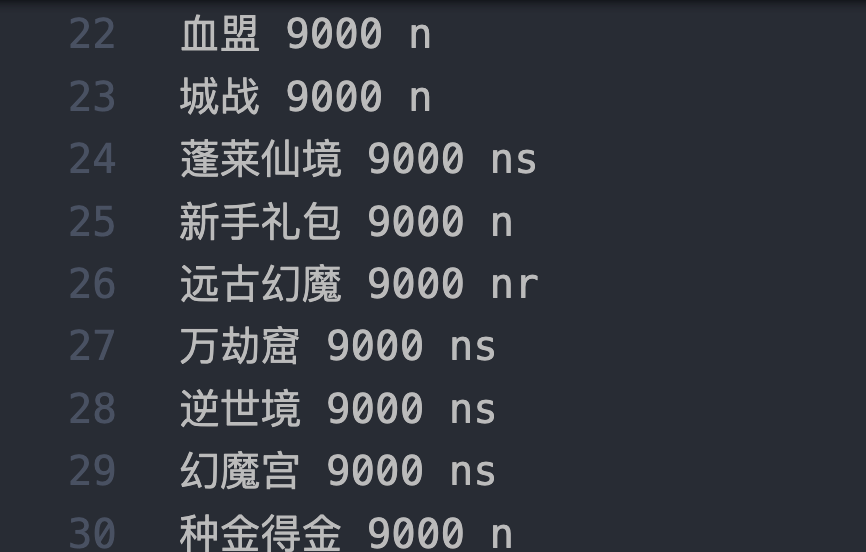
一般来说,词性设置简单:
1
2
3
4
5
6
7
|
n 名词
nr 人名/专名
ns 地名
v 动词
a 形容词
m 数量词
eng 英文词
|
领域词大多数直接写 n 就够了。
做这个字典,一般是 人工种子词 + 文档自动抽取 + 人工筛选/校正 三步做出来的(也可以用自动工作流或者 llm 提取),业务逻辑处理大概是:
1
2
3
4
5
6
7
8
9
|
准备领域文档
-> 自动抽取候选词
-> 统计词频
-> 人工筛掉垃圾词
-> 补充核心业务词
-> 生成 user_dict.txt
-> 加载到 tokenizer
-> 用检索效果反复调整
|
- 人工种子词可以是业务方提供,也可以是运营同学提供,也可以是运营同学从文档里抽取,也可能是爬取的,总之就是数据来源多样,但是格式统一。
- 可以使用从上述来源中,用jieba.analyse、textrank、TF-IDF、n-gram 等等方式抽抽选词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
# 极简示例
import jieba.analyse
from collections import Counter
from pathlib import Path
def extract_terms_from_files(paths):
counter = Counter()
for path in paths:
text = Path(path).read_text(encoding="utf-8", errors="ignore")
terms = jieba.analyse.extract_tags(
text,
topK=200,
withWeight=False,
allowPOS=("n", "nr", "ns", "nt", "nz", "vn", "eng"),
)
counter.update(terms)
return counter
paths = [
"docs/a.txt",
"docs/b.txt",
]
terms = extract_terms_from_files(paths)
for word, freq in terms.most_common(100):
print(word, freq, "n")
# 弑神修炼 5000 n
# 护具制作 5000 n
# 武器打造 5000 n
# 炼金制作 5000 n
# 符文制作 5000 n
# 血盟任务 5000 n
|
- 至于上面的词频怎么填,其实没有啥金标准,它本质是告诉分词器“这个词重要”。
- 词性按照准备的词表填即可
- 人工筛选很重要!!!要去除噪声词,例如会抽出下面这些:
1
2
3
4
5
6
|
本文
进行
通过
以及
相关
结果显示
|
这些词如果进词典,会污染检索。所以要人工筛一遍。
更好的方式是做两个文件:
1
2
|
domain_userdict.txt # 要加入的领域词
domain_stopwords.txt # 不要加入的停用词
|
- 大概得处理流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
import re
import jieba.analyse
from pathlib import Path
from collections import Counter
STOPWORDS = {
"本文", "进行", "通过", "以及", "相关", "结果", "显示",
"研究", "分析", "使用", "方法", "系统",
# 总之,你有你的停用词domain_stopwords.txt
}
def clean_word(word: str) -> bool:
if not word:
return False
if word in STOPWORDS:
return False
if len(word) < 2:
return False
if re.fullmatch(r"\d+", word):
return False
return True
def extract_domain_dict(input_dir: str, output_file: str):
...
with open(output_file, "w", encoding="utf-8") as f:
for word, count in counter.most_common(1000):
freq = min(9000, max(1000, count * 1000))
f.write(f"{word} {freq} n\n")
extract_domain_dict(
input_dir="docs",
output_file="domain_userdict.txt",
)
|
以上是通用的处理,接下来是重头戏,分享一下我们游戏领域的自定义处理:
2. 自定义分词器
为了给我们服务于游戏场景下的 RAG 系统服务,我们的分词器也做了单独的设计:
2.0 字典分类设计
首先是字典分类,这步很重要,我们把游戏内的词典分为了六类:
1
2
3
4
5
6
|
1. 游戏专名:游戏名、简称、资料片名、版本名
2. 角色体系:职业、门派、种族、阵营、NPC、主角名
3. 玩法系统:副本、任务、帮派、师门、宠物、坐骑、装备强化、交易、PK
4. 数值属性:攻击、防御、法攻、暴击、命中、闪避、气血、法力、抗性
5. 道具技能:装备名、技能名、材料名、药品名、宝石名、召唤兽名
6. 玩家黑话:简称、别名、缩写、俗称,比如 “战士/战”、“法师/法”、“副本/本”
|
词性:
1
2
3
4
|
eng:英文词
ns:地图/地点,如 通天塔、幻魔宫、万劫窟
nr:角色/BOSS/职业倾向,如 战士、法师、世界boss
n:默认名词
|
除了运营、市场、策划、游戏侧给出的文本资料,我们可以直接文档处理提取的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
1. 官方资料库
职业、技能、装备、任务、副本、NPC、地图、道具、活动
2. 结构化业务数据
数据库表、配置表、Excel、后台 CMS、商品/道具/技能配置
3. 文档语料自动抽取
FAQ、攻略、公告、客服问答、wiki、论坛精品帖
4. 搜索日志
用户真实搜索词、未命中 query、低点击 query
5. 问答日志
用户问法、LLM 回答失败问题、人工客服转写问题
6. 同义词和黑话
玩家简称、俗称、缩写、拼音、错别字
7. 人工专家维护
运营、策划、客服、领域专家审核
|
但是有的老项目依赖的一些原始文档不全,只有网页了,对于反爬不厉害的,我们单独做了爬虫服务,单独处理:
1
2
3
4
5
6
7
8
9
|
游戏资料站/wiki/营销活动页
-> 爬取栏目页
-> 提取标题、表格、列表、加粗词、导航词
-> 清洗候选词
-> 合并同义词/别名
-> 生成人工可审查的 domain_userdict.txt
-> 加载进 tokenizer
-> 重新入库文档
-> 用真实问题测召回
|
2.1 按照词源优先级拆分:
优先处理下面这些
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
职业/门派
技能
装备
道具
副本
任务
宠物/召唤兽
坐骑
地图
NPC
怪物
系统玩法
版本资料片
新手指南
FAQ
|
这些页面里的标题、表格第一列、技能名、装备名、NPC 名,都是高价值领域词!!!
2.2 自动抽候选词
不能单纯的靠extract_tags()。应该按照某种格式进行:“结构化抽取 + 统计抽取”结合。
优先级从高到低:
1
2
3
4
5
6
7
8
|
页面 title
h1/h2/h3 标题
导航菜单文本
表格 th/td,尤其第一列
列表 li
加粗 strong/b
链接文本 a
正文里的高频 n-gram
|
比如页面里有表格:
1
2
|
技能名称 | 技能类型 | 学习等级 | 技能说明
烈火剑法 | 主动技能 | 35 | 对目标造成高额物理伤害
|
按照约定的结构,应该直接抽:
1
2
3
4
|
烈火剑法
主动技能
学习等级
物理伤害
|
2.3 游戏词典格式
我们游戏内,按照
1
2
3
4
5
6
7
8
9
|
职业/门派/种族/阵营:9000 n
技能名:9000 n
装备名:8500 n
副本名:8500 n
NPC/角色名:8000 nr
地图名:7500 ns
材料/道具名:7000 n
玩法系统名:6000 n
玩家简称/黑话:5000 n
|
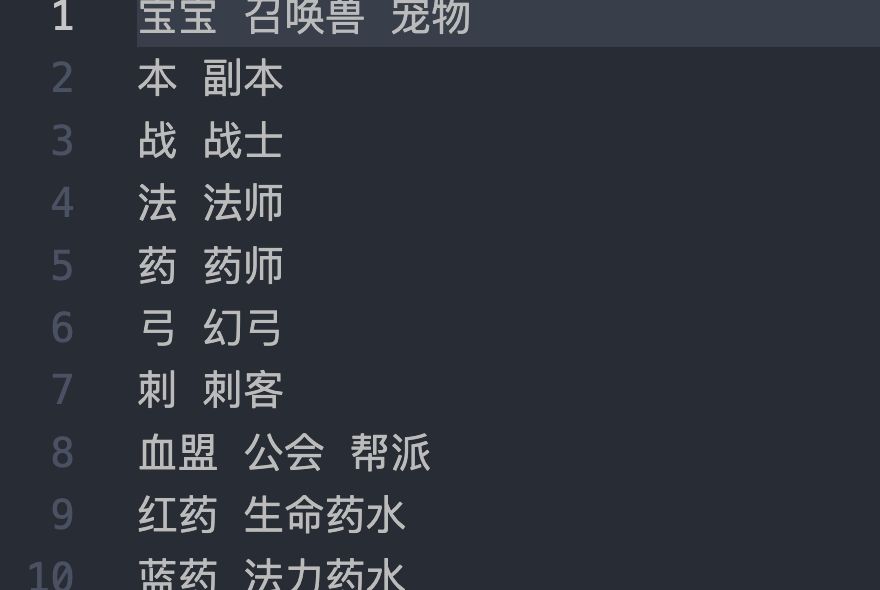
其中游戏内 RAG 不同的一点是,玩家的问法和官方很不一样,口语化的太多了,需要额外维护一张别名表:
1
2
3
4
5
6
7
8
|
战 战士
法 法师
道 道士
宝宝 召唤兽
本 副本
红药 生命药水
蓝药 法力药水
强化 装备强化
|
最终形成:
📢注意:有一些人的做法是,将同名词典追加到主词典中,形成:
1
2
3
4
5
6
7
8
|
战士 9000 n
战 5000 n
法师 9000 n
法 5000 n
召唤兽 8000 n
宝宝 6000 n
副本 8000 n
本 5000 n
|
但是经过测试,有时候同义词命中率不是很理想,我觉得更好的做法是:
- 词典负责“不切坏”
- 同义词表负责“查询扩展”
也就是说,当用户问:
query 扩展成:
同义词词典,不应该杂糅到大辞典中,应该作为 query 的优化点——expansion query,增强 query召回,这样比只靠词典更稳。
2.4 如何处理高频词
前面通用处理说了,有的高频词是噪声,会污染检索,人工检查时,应该剔除,例如下列词尽量不进入领域词典:
但是,在游戏中,上述的词会和游戏进行组合,形成有效的领域词,这点是要注意的,例如游戏内的组合词:
1
2
3
4
5
6
7
|
获得经验
宝石等级
学习等级
主线任务
日常任务
师门任务
...
|
这些组合词,在实际测试中发现,需要被召回的,比单个泛词更有价值,所以需要保留。
!!!这一点,也是以后做不同领域的分词器时,需要考虑的,如何平衡高频词和泛词。
2.5 简单的代码示例
伪代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
from bs4 import BeautifulSoup
from collections import Counter
import re
HIGH_VALUE_SELECTORS = [
"title",
"h1", "h2", "h3",
"th", "td",
...
]
STOPWORDS = {
# 停用词设计,优化点之一
"首页", "更多", "返回", "下载", "注册", "登录",
"可以", "需要", "进行", "相关", "介绍", "说明",
...
}
def clean_term(text):
# 前置数据清洗方法
text = re.sub(r"\s+", "", text or "")
text = re.sub(r"[::,,。.!!??()\[\]【】<>《》]", "", text)
return text
def is_good_term(term):
# 过滤噪声词,很重要,是优化点之一
...
def extract_terms_from_html(html):
soup = BeautifulSoup(html, "html.parser")
counter = Counter()
for selector in HIGH_VALUE_SELECTORS:
for node in soup.select(selector):
term = clean_term(node.get_text())
if is_good_term(term):
counter[term] += 3
text = soup.get_text("\n")
for term in re.findall(r"[\u4e00-\u9fa5A-Za-z0-9]{2,12}", text):
term = clean_term(term)
if is_good_term(term):
counter[term] += 1
return counter
def guess_pos(term):
# 词性判断
if term.endswith(("城", "村", "山", "谷", "洞", "宫")):
return "ns"
if term.endswith(("王", "魔", "仙", "神", "妖")):
return "nr"
return "n"
# 打分权重 按照业务讨论的领域定制
SOURCE_WEIGHTS = {
"title": 12,
"keywords": 10,
"heading": 9,
"link": 7,
"table": 6,
"strong": 6,
"list": 5,
"jieba": 2,
}
# title 里的词 +12 分
# meta keywords 里的词 +10 分
# h1-h5 标题里的词 +9 分
# 链接文本里的词 +7 分
# 表格里的词 +6 分
# 加粗词 +6 分
# 列表项 +5 分
# jieba 提取正文中的关键词 +2 分
def add_term(
scores: Counter[str],
sources: dict[str, set[str]],
**kwargs
):
...
# 根据权重,加分
scores[candidate] += SOURCE_WEIGHTS[source] * multiplier
sources[candidate].add(f"{source}:{page}")
...
def calc_freq(count):
# 词频推断 示例
if count >= 20:
return 9000
if count >= 10:
return 7000
if count >= 5:
return 5000
return 3000
def write_userdict(counter, output):
with open(output, "w", encoding="utf-8") as f:
for term, count in counter.most_common():
freq = calc_freq(count)
pos = guess_pos(term)
f.write(f"{term} {freq} {pos}\n")
|
最终生成多个词典:
1
2
3
4
|
rag/res/game_userdict.txt # 游戏领域词典
rag/res/game_synonyms.txt # 玩家黑话/别名
rag/res/game_stopwords.txt # 垃圾词
rag/res/game_terms_review.csv # 人工审核候选词
|
总结下来就是:
1
2
3
4
5
6
7
8
|
清洗垃圾词
= clean_text() + is_good_term() + STOPWORDS + NOISE_PATTERNS
给候选词打分
= SOURCE_WEIGHTS + add_term() + Counter 累加
推断词频和词性
= score_to_freq() + guess_pos()
|
2.6 端到端检索测试
有人可能会觉得词典越大越好,实际并不是的,需要平衡性能和效果,如果词典太大,检索性能会下降,召回效果也会下降。
我们的业务场景中,游戏领域词典来源占比分配是:
1
2
3
|
官方资料站结构化抽取 70%
玩家黑话/简称人工补充 20%
召回测试后迭代修正 10%
|
👨🏻💻 要记住分词器核心原则:不要只看词典数量,要看RAG 能不能召回正确 chunk!!!
测试方式大概如下:
- 按照项目要求,准备好测试文档,测试问题应该覆盖玩家真实问法:
1
2
3
4
5
6
7
|
战士怎么加点?
宝宝怎么升级?
哪个副本掉高级装备?
装备强化失败会怎么样?
法师前期带什么技能?
帮派任务在哪里接?
...
|
- 入库后看 ES 中每个 chunk 的字段:
1
2
3
|
content_with_weight
content_ltks
content_sm_ltks
|
- 看 top 5 召回结果是否包含正确 chunk。
例如文档里有:
血盟据点战在幽冥库地下一层 拐角处、血魔战场入口处。
测试问题:
我怎么打血盟战?
- 如果召回 top 结果里有这段,说明 tokenizer + ES 检索是有效的。
- 如果召回不到:
1
2
3
4
5
|
1. 看 query 有没有被正确分词
2. 看文档 content_ltks 有没有对应词
3. 看 content_sm_ltks 有没有兜底词
4. 看别名是否缺失
5. 看是不是领域词没进 userdict
|
所以好用的 tokenizer 应该满足:
- 重要业务词不要被过度拆碎。
- 用户问题里的关键词能和文档 token 对上。
content_ltks 偏精准。
content_sm_ltks 能补召回。
- 英文技术词、数字、小数、版本号不要乱。
2.7 验收标准
基于上一节的分词器的测试原则,我们设计了 4 层验收标准:
1. 文件格式验收
目标:证明 xxx_userdict.txt、*.txt 能被 tokenizer 加载。
验收标准:
1
2
3
4
5
6
7
|
每行必须是:词 频率 词性
词不能为空
频率必须是数字
不能有 HTML 标签
不能有 URL
不能有纯数字词
不能有空格词
|
2. 核心词覆盖验收
目标:证明资料站里的核心游戏词被抽到了。
和运营、策划,一起讨论,制定一个我们领域内的 gold list:
1
2
3
4
5
6
7
8
9
10
|
七杀阵
阪泉擂台赛
坐骑捕获培养
血盟据点战
坐骑系统
血盟系统
装备强化
通天塔
九幽界战场
...
|
验收指标:
核心词覆盖率 = 命中的核心词数量 / gold list 总数
例如我们问:“战士20级七杀阵和坐骑捕获培养怎么做”,
必须命中:
验收标准:核心词覆盖率 >= 90%
3. 分词效果验收
目标:证明加载词典后,领域词不会被切碎。
例如测试句:
不用词典:
1
|
战士 20 级 七 杀阵 和 坐骑 捕获 培养 怎么 做
|
加载词典后:
1
|
战士 20级七杀阵 和 坐骑捕获培养 怎么 做
|
说明我们的核心领域词:
被保护成完整词。
验收指标:
1
|
领域词保护率 = 保持完整的领域词数量 / 测试领域词总数
|
验收标准:
4. 词典质量验收
这个最重要。因为总有一些意外情况,看似有些词虽然格式正确,但质量一般,比如:
1
2
3
4
|
被神化的史诗传说
超大规模的万人城战
轩辕传奇官方网站
进入轩辕传奇官方网站
|
这些偏营销词,不一定适合进最终词典。
所以要看 xxx_review.csv,人工标注前 xxx 个词:
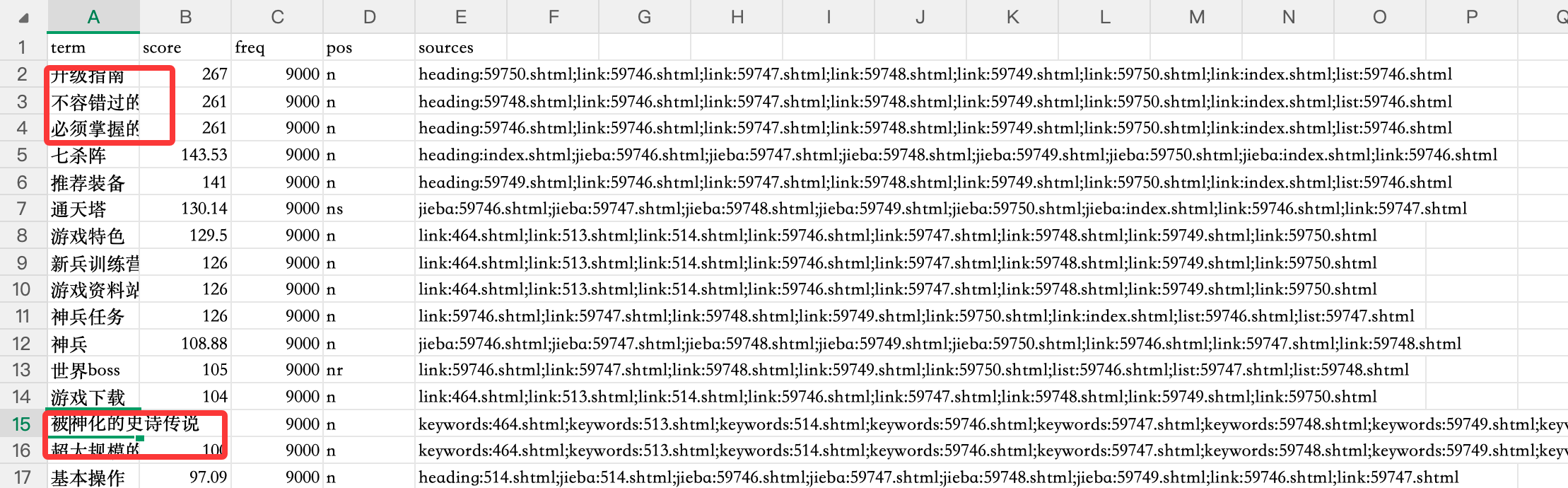
1
2
|
good:游戏实体/玩法/系统/职业/任务/副本/装备
bad:营销词/导航词/泛词/半截词
|
验收指标:
1
|
Top100 精准率 = Top100 中 good 数量 / 100
|
建议标准:
如果低于 80%,继续加停用词或调低某些来源权重,比如 keywords 里容易出营销词。
5. RAG 召回验收
又回到上一节我们的测试原则上了,再复习一遍:
最终不是看词典漂亮,而是看检索能不能召回正确 chunk。
测试问题:
1
2
3
4
5
6
7
|
战士20级做什么任务?
七杀阵怎么玩?
坐骑捕获培养在哪里?
血盟据点战怎么参加?
阪泉擂台赛有什么奖励?
法师推荐装备是什么?
...
|
入库后看 ES top k。
指标:
1
2
|
Hit@5 = 前 5 个召回结果中是否包含正确资料 chunk
MRR = 正确 chunk 排名越靠前越好
|
验收标准:
1
2
|
Hit@5 >= 80%
MRR >= 0.5
|
其中关于这个倒数排名为啥才 0.5呀,我查了相关资料,算法同学也说了,这是工程经验值,并不像我一开始以为的越高越好🤣
绝大多数检索/问答/推荐场景,用户只会看前1、前2条:
- MRR > 0.5:合格
正确结果普遍在前两位,用户不用翻很多条,业务可用;
- MRR = 0.3~0.5:勉强能用,体验一般,经常要往下翻;
- MRR < 0.3:不合格,平均正确答案掉到第3名及以后,用户大概率划走、找不到答案,体验崩盘。
很多检索、RAG、问答数据集(如MS MARCO、FAQ检索、文档召回)通用经验基线:
- 入门基线:MRR ≥ 0.5
- 良好模型:MRR ≥ 0.7~0.8(大量样本命中第1位)
- 优秀模型:MRR ≥ 0.9(绝大多数正确结果置顶)
MRR≥0.5 本质是一条用户体验硬门槛:
平均意义上,正确答案至少稳定出现在返回列表前两位,不会大量落到第三名及以后,业务场景下才算具备使用价值,因此被广泛定为合格标准。
我们的验收表
| 层级 |
指标 |
合格标准 |
| 文件格式 |
坏行数 |
0 |
| 抓取覆盖 |
成功页面数 |
>= 目标 max-pages 的 90% |
| 核心词覆盖 |
gold list 命中率 |
>= 90% |
| 分词保护 |
领域词完整保留率 |
>= 90% |
| 词典质量 |
Top100 人工精准率 |
>= 80% |
| RAG 效果 |
Hit@5 |
>= 80% |
| RAG 效果 |
MRR |
>= 0.5 |
3. 工程优化
以上两节基本介绍完了分词器,咋处理,本节主要讲讲工程优化,其实项目做起来,从软件开发的角度来说,本节才是核心呀。
3.1 字典的处理优化
这部分其实,我觉得有点啰嗦了,在 2.1 节其实讲的不少了,但是为啥我还想单独记录呢,因为在做的过程中,其实这部分花时间精力可不少,尝试了多个渠道和对比方法,当结果不是很理想时,万万没想到源头字典上还大有动手空间呀,尤其是做完之后,也只能感叹一句,谁做谁知道,一家一个样🤣🤣🤣
我们的经验来说,就四种方式处理数据,并生成字典:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
1. 官方配置数据
-> 规则抽取 name 字段
-> 直接进入高置信词典
2. 官方资料站
-> HTML 结构抽取
-> 打分
-> 进入审核表
3. 搜索日志/玩家问法
-> 高频 query / 未命中 query
-> 与官方词匹配
-> 生成同义词候选
4. 攻略/FAQ/论坛
-> TF-IDF/TextRank/LLM 抽实体
-> 低置信候选
-> 人工审核
人工审核
-> userdict.txt
-> synonyms.txt
-> stopwords.txt
-> versioned dictionary
|
而且啊,经验告诉我:能用结构化字段解决的,不要先上模型。
稍微展开上面的四种格式处理方法:
1. 官方配置数据
这是最高质量来源。比如游戏内部有:
1
2
3
4
5
6
7
|
skill_config.csv
item_config.csv
monster_config.csv
npc_config.csv
map_config.csv
quest_config.csv
activity_config.csv
|
字段处理的完美极了😄:
1
2
3
4
|
id,name,type,level,desc
1001,七杀阵,副本,20,20级开放的组队玩法
2001,坐骑捕获培养,系统,25,坐骑捕获与培养说明
3001,赤焰剑,装备,30,战士武器
|
喜大普奔呀,我直接取 name 字段,再根据表名/类型生成词性和频率。
例如:
1
2
3
4
5
6
7
8
9
|
TABLE_RULES = {
"skill_config.csv": ("n", 9000),
"item_config.csv": ("n", 8500),
"monster_config.csv": ("nr", 8500),
"npc_config.csv": ("nr", 8500),
"map_config.csv": ("ns", 8500),
"quest_config.csv": ("n", 8000),
"activity_config.csv": ("n", 8000),
}
|
生成:
1
2
3
4
5
|
七杀阵 9000 n
坐骑捕获培养 9000 n
赤焰剑 8500 n
赤月恶魔 8500 nr
比奇城 8500 ns
|
这种不需要模型,规则最稳。
2. 官方资料站结构化字段
资料站虽然是 HTML,但里面有结构。
优先抽:
1
2
3
4
5
6
7
8
|
title
h1/h2/h3/h4/h5
表格第一列
a 标签文本
导航栏目
列表标题
strong/b
meta keywords
|
比如:
1
2
3
|
<h5>七杀阵</h5>
<a>坐骑捕获培养</a>
<td>血盟据点战</td>
|
这些可以直接当候选词。
处理方式:
1
2
3
4
5
6
|
抽结构化字段
-> 清洗导航词/营销词
-> 按来源打分
-> 输出 review.csv
-> 人工确认
-> 进入 userdict
|
这两部分就是我们 2.1节做的事情,事实证明,这些工作虽然繁琐,但是很有意义呀!!!
3. 搜索日志/玩家问法
搜索日志,游戏侧给出来的长这样:
1
2
3
4
5
|
query,count,clicked_doc,has_answer
宝宝怎么升级,123,召唤兽培养,false
七杀怎么打,98,七杀阵攻略,true
战士加点,80,战士职业攻略,true
坐骑在哪抓,56,坐骑捕获培养,true
|
这里成分是不是有点复杂呀,不过我们主要用来生成两类东西:
- 领域词典
- 同义词/别名表
处理方式:
1
2
3
4
5
6
|
高频 query
-> 分词
-> 抽 n-gram
-> 找未命中 query
-> 和官方词做相似匹配
-> 生成人工审核表
|
例如:
如果官方词里有:
那生成同义词:
再比如:
和官方词:
匹配,就生成:
这一步可以用模型,下一节单独讲用模型咋做。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
**4. 自动关键词抽取怎么处理**
这类质量最低,适合补充候选词。
来源:
```text
攻略正文
公告正文
FAQ
论坛精选帖
客服问答
|
方法:
1
2
3
4
5
|
TF-IDF
TextRank
n-gram 高频短语
NER 实体识别
LLM 抽取
|
但抽完不能直接入词典,要进审核表。
比如模型/算法抽到:
1
2
3
4
5
6
|
幻魔宫
弑神进阶
药师治疗
血盟联赛
强大的群体攻击
必须掌握的技巧
|
其中:
1
2
3
4
|
幻魔宫
弑神进阶
药师治疗
血盟联赛
|
是好词。
偏描述/标题,不一定适合入词典。
5. 啥时候用大模型处理呢
大模型可以用,但是用的方法就很讲究了,通过经验,我们认为建议放在两个位置。
第一,实体抽取:
让模型从文本里抽如下的东西:
1
2
3
4
5
6
7
|
{
"skills": ["烈火剑法", "弑神技能"],
"items": ["赤焰剑", "生命药水"],
"maps": ["幻魔宫", "万劫窟"],
"quests": ["七杀阵", "百环任务"],
"systems": ["坐骑捕获培养", "装备强化"]
}
|
适合处理非结构化攻略、公告、FAQ。
第二,同义词归并:
让模型判断:
1
2
3
4
|
宝宝 -> 召唤兽
本 -> 副本
七杀 -> 七杀阵
红药 -> 生命药水
|
但是!!!经验告诉我们,不要让模型直接写最终词典,应该让它生成:
然后人工审核或规则校验,总之不要相信大模型,直接入字典。
最终输出一般分 4 个文件
给 tokenizer 用:
1
2
3
4
|
七杀阵 9000 n
坐骑捕获培养 9000 n
幻魔宫 8500 ns
赤月恶魔 8500 nr
|
给 query 扩展用:
1
2
3
4
|
宝宝 召唤兽 宠物
七杀 七杀阵
本 副本
红药 生命药水
|
过滤垃圾词:
1
2
3
4
5
6
|
点击
查看
更多
官网
介绍
说明
|
人工审核:
1
2
3
|
term,source,type,score,status,evidence
七杀阵,quest_config,activity,0.99,approved,quest_config.csv:1001
宝宝,search_log,synonym,0.86,pending,top query 123次
|
借用我们组当时关于分词器字典的会议总结:
- 结构化数据规则抽取为主
- 资料站结构抽取辅助
- 搜索日志补玩家叫法
- 模型用于非结构化文本抽候选和同义词归并
- 最后用人工审核和检索指标闭环
- 模型是增强工具,不是唯一核心。
3.2 怎么用 LLM
始终牢记“不要让模型直接生成最终词典”,而是用模型
1
2
3
4
5
|
抽候选实体:
-> 输出结构化 JSON
-> 程序校验/去重/打分
-> 人工审核
-> 再生成 userdict.txt / synonyms.txt
|
为什么不能完全相信模型
模型会犯这些错:
1
2
3
4
5
|
把句子当词
抽出营销词
编造别名
类型判断错误
遗漏低频但重要实体
|
所以必须保留:
1
2
3
4
|
evidence 原文证据
confidence 置信度
review.csv 人工审核
规则校验
|
约束 LLM 的数据结构
对我们的游戏领域来说,模型适合抽这些结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
{
"terms": [
{
"term": "七杀阵",
"type": "activity",
"aliases": ["七杀"],
"confidence": 0.95,
"evidence": "20级七杀阵是组队玩法"
},
{
"term": "坐骑捕获培养",
"type": "system",
"aliases": ["坐骑培养", "抓坐骑"],
"confidence": 0.91,
"evidence": "坐骑捕获培养"
}
]
}
|
我们为此次设计的字段:
1
2
3
4
5
|
term:标准词
type:实体类型
aliases:玩家可能叫法
confidence:模型置信度
evidence:来自原文的证据
|
LLM 实现
针对2.1 节的大模型实现流程
1
2
3
4
5
6
7
8
9
|
HTML 页面
-> 提取正文 text
-> 按 2000-4000 字切块
-> 调模型抽实体 JSON
-> 校验 JSON
-> 合并相同 term
-> 根据 type/source/confidence 打分
-> 生成 review.csv
-> 人工确认后生成词典
|
Prompt 示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
你是游戏资料词典构建助手。
请从下面的游戏资料文本中抽取适合 RAG 检索分词词典的领域词。
只抽这些类型:
- profession: 职业/门派/角色职业
- skill: 技能
- item: 道具/装备/材料
- npc: NPC/BOSS/怪物
- map: 地图/场景
- quest: 任务
- activity: 副本/活动/玩法
- system: 游戏系统
- attribute: 数值属性
不要抽:
- 普通描述词
- 营销词
- 导航词
- “更多/查看/进入/介绍/说明”
- 太长的句子
返回 JSON:
{
"terms": [
{
"term": "标准词",
"type": "activity",
"aliases": ["别名1", "别名2"],
"confidence": 0.0-1.0,
"evidence": "原文证据"
}
]
}
文本:
...
|
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
import json
import os
from openai import OpenAI
client = OpenAI(
api_key=xxx,
base_url=xxx,
)
def extract_terms_by_llm(text: str) -> list[dict]:
prompt = build_prompt(text)
resp = client.chat.completions.create(
model=" xxx",
messages=[
{"role": "system", "content": "你只输出合法 JSON,不要输出解释。"},
{"role": "user", "content": prompt},
],
temperature=0.1,
)
content = resp.choices[0].message.content
data = json.loads(content)
return data.get("terms", [])
|
把之前的设计的 json 字段类型映射到词性
1
2
3
4
5
6
7
8
9
10
11
|
POS_BY_TYPE = {
"profession": "nr",
"skill": "n",
"item": "n",
"npc": "nr",
"map": "ns",
"quest": "n",
"activity": "n",
"system": "n",
"attribute": "n",
}
|
置信度转频率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def confidence_to_freq(confidence: float, source: str) -> int:
base = 7000
if source == "official_config":
base += 2000
elif source == "official_site":
base += 1000
if confidence >= 0.9:
return min(base + 1000, 9000)
if confidence >= 0.75:
return base
if confidence >= 0.6:
return 5000
return 3000
|
合并逻辑
同一个词可能多个页面都抽到:
1
2
3
4
5
6
7
8
9
10
|
merged = {
"七杀阵": {
"type": "activity",
"confidence": 0.95,
"count": 8,
"sources": [...],
"aliases": {"七杀"},
"evidence": [...]
}
}
|
最终打分可以这样:
1
2
3
4
5
|
final_score =
confidence * 50
+ 页面出现次数 * 5
+ 来源权重
+ 是否有标题/表格证据
|
** 最终输出 userdict.txt**
最终融合LLM 的推荐架构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
结构化配置表
-> 规则抽取,高置信,直接入候选
官网资料页
-> HTML 结构抽取 + LLM 抽取,互相补充
玩家搜索日志
-> 统计 query + embedding/LLM 归并别名
模型输出
-> review.csv
-> 人工审核 approved/rejected
-> 生成 userdict/synonyms/stopwords
-> RAG 召回评估
|
模型绝对不能替代规则,而是可以配合补充下面这两块:
- 从非结构化正文中识别实体
- 把玩家叫法和官方词归并成同义词
对于官方配置表、HTML 标题、表格字段,规则更稳;对于攻略正文、FAQ、玩家问法,模型更有价值。
3.3 自定义分词器架构
🌿 ,不知不觉写了这么多,有点累了……
看来代码架构实现,得下一篇总结了,今天先到这吧,算是抛砖引玉了,要是觉得有启发,给俺文章留言讨论呀,哈哈哈……