RAG设计之PDF解析器优化
文章目录
本文主题是 pdf 解析器,是离线解析文档的入口,也是比较难的一部分,因为 PDF 里面的内容比较复杂,需要考虑很多细节。 例如:表格数据(尤以多个表格排布最难)、图片、页脚引用等等。本文使用到的资料均已脱敏,不涉及到任何公司隐私,仅做个人复盘。
1. 缘起
从零手写一个PDF解析器,确实比较难,幸好中台组的small他们搞到了一个开源的解析器,我在此基础上做了工程化的改造,使其符合我们的游戏内 RAG 应用需要。
这个解析器的核心流程是:
- PDF 页面渲染
- OCR
- Layout 识别
- Table Structure 识别
- 文本块合并
- 给文本追加坐标 tag,记录页码,上右下左的坐标值。例如:

它本质上这是一个依赖视觉模型 OCR的解析器,通过后训练过的模型进行处理 PDF 数据,来保证准确:
flowchart LR A["nlp/vision/ocr.py"] --> B["rag/res/deepdoc/det.onnx"] A --> C["rag/res/deepdoc/rec.onnx"] A --> D["rag/res/deepdoc/ocr.res"] E["layout_recognizer.py"] --> F["layout.onnx / layout.paper.onnx / layout.manual.onnx / layout.laws.onnx"] G["table_structure_recognizer.py"] --> H["tsr.onnx"] I["pdf_parser.py"] --> J["updown_concat_xgb.model"]
中台组的算法小伙伴负责微调视觉模型,各个文件作用:
det.onnx:OCR 文本检测。rec.onnx:OCR 文本识别。layout*.onnx:不同领域 PDF 的版面识别模型。tsr.onnx:表格结构识别模型。updown_concat_xgb.model:判断上下文本块是否应拼接的 XGBoost 模型。ocr.res:OCR 字典或相关识别资源。
用到的核心第三方库是:
|
|
识图说话。
2. 工程化改进
按理说这个开源的解析器已经比较完善了,但是当运营老大用台服的 PDF 测试时,发现解析出来的数据有问题,例如:
- 繁体乱码
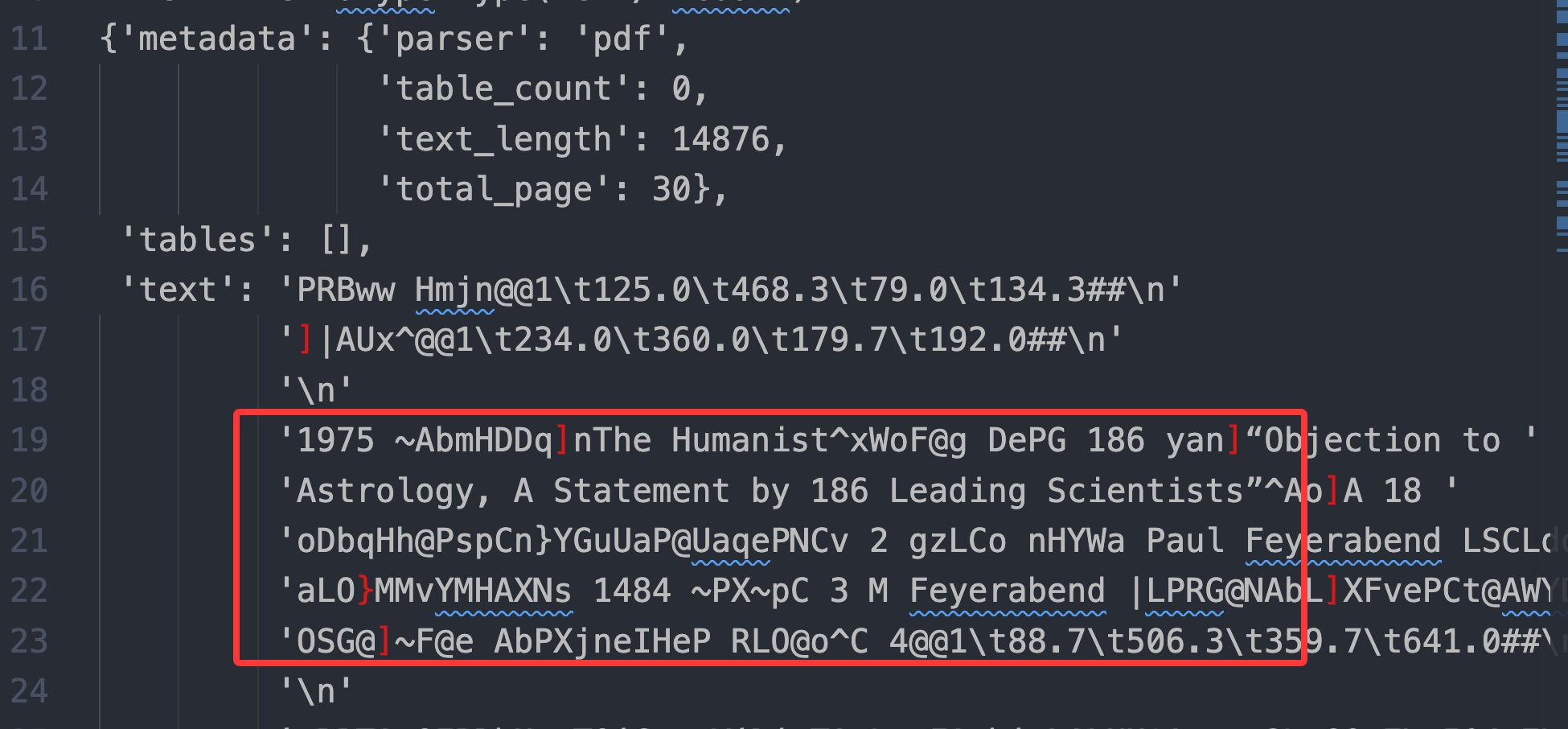 ,这对中文繁体好像不兼容啊,直接乱码了
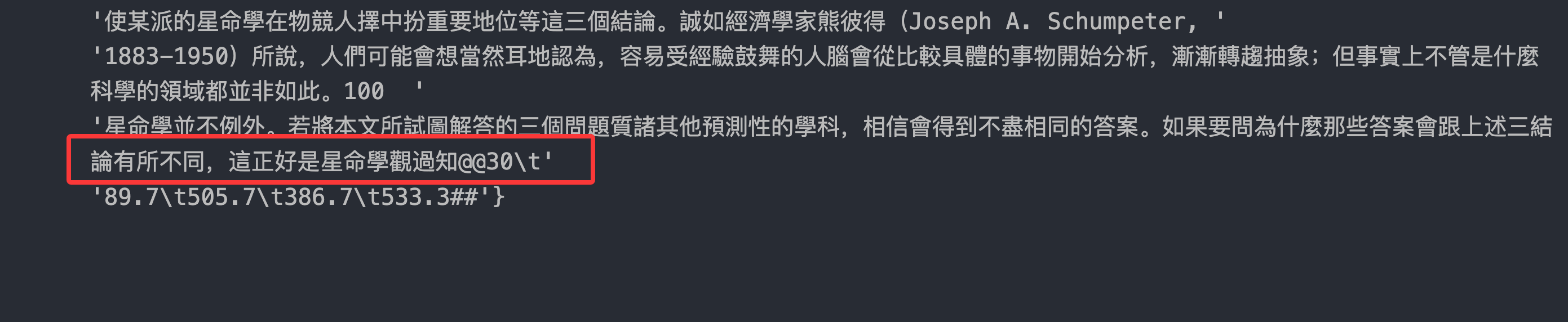
,这对中文繁体好像不兼容啊,直接乱码了 - 页尾内容丢失

- 引用识别错误

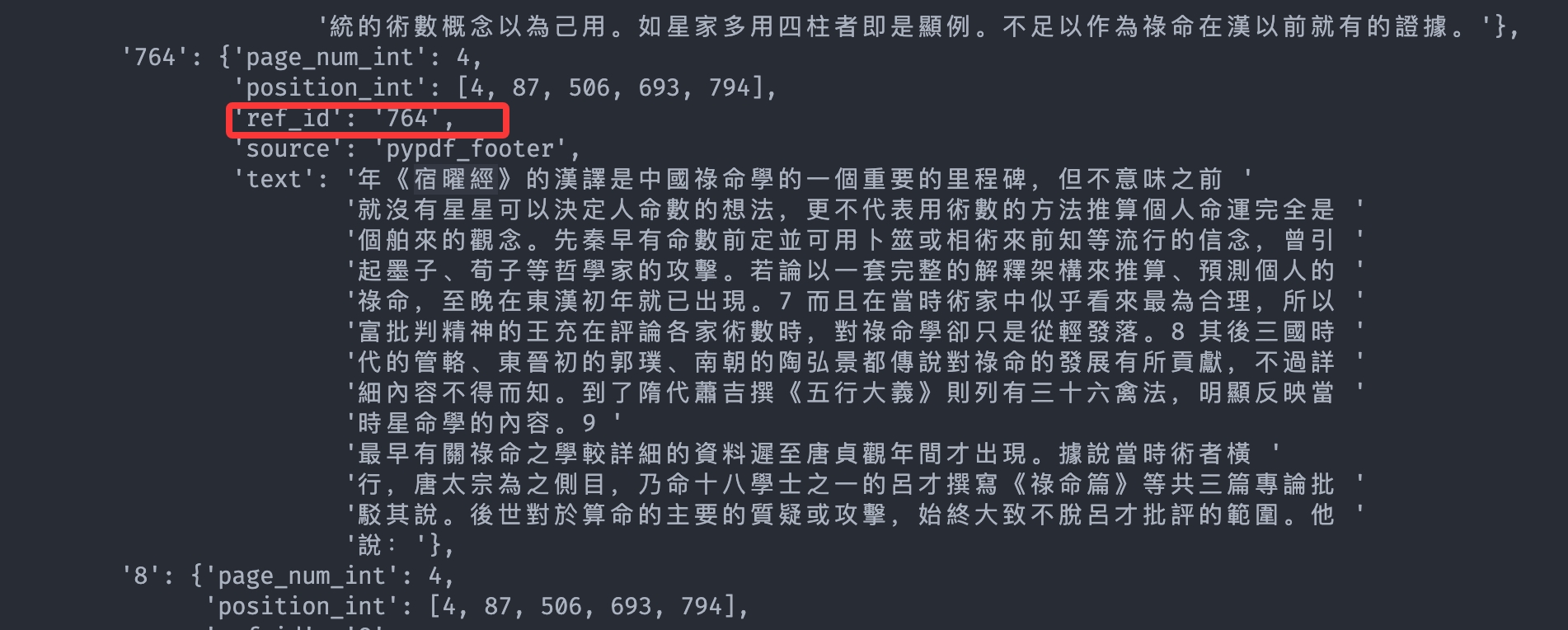 这些其实不是引用,而是正文内容,正确的引用应该是这种:
这些其实不是引用,而是正文内容,正确的引用应该是这种:

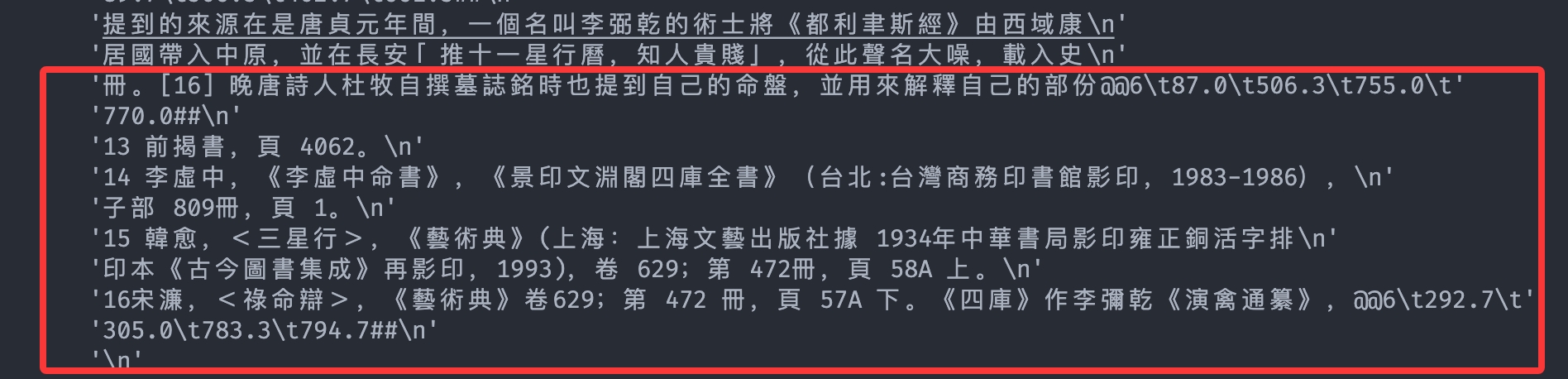
- 目前的复杂解析速度慢,有些简单的 pdf 不用 OCR 也能解析出来,没必要走 OCR 等等流程
- 等等……
怎么解决问题呢?其他识别精度算法上的问题可以交给中台,这几个我可以从工程化角度上,解决。
2.1 繁体乱码
通过分析数据,我发现虽然乱码了,但是期望文本块的坐标值是正确的
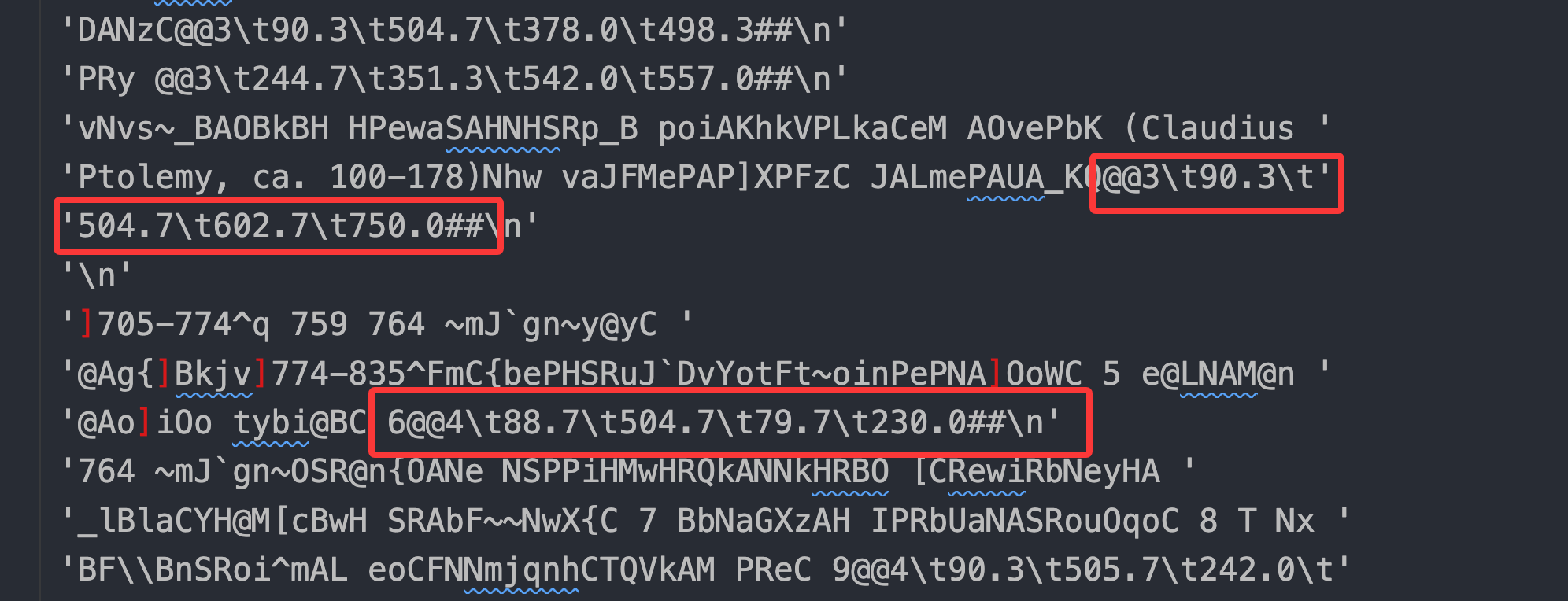 符合
符合@@page\tleft\tright\ttop\tbottom的格式,表示在第几页,块的左右坐标,顶部坐标,底部坐标,这样矩形框就可以绘制了。
稍微补一下前置背景(这是伏笔 1👨🏻💻,下一章会重点介绍 parser 的整体架构设计):
在此只是简单介绍一下原架构中 :
- pdfplumer把每页 PDF 解析生图片,同时再处理文本,生成上面带坐标的文本字符串
- 然后通过 OCR 识别文本框,也打上标签
- 用坐标匹配的方法,把对应的文本框和 OCR 识别的文本匹配起来,最终生成带坐标的文本块。
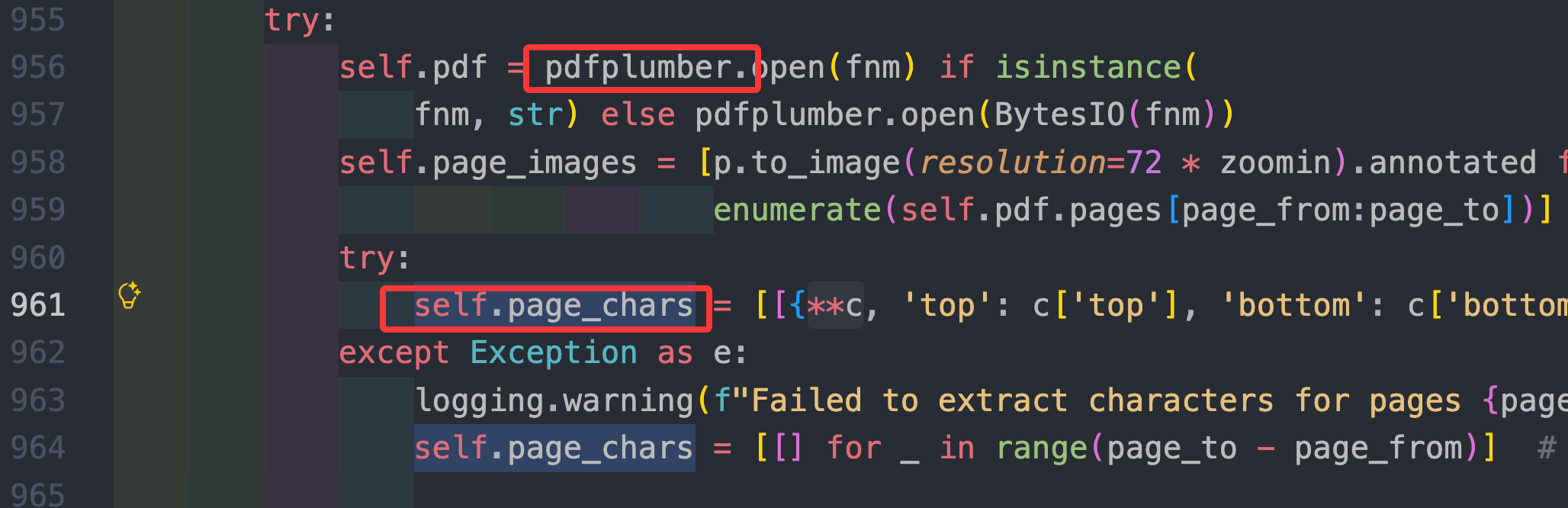
- images() 先用 pdfplumber 取字符:
|
|
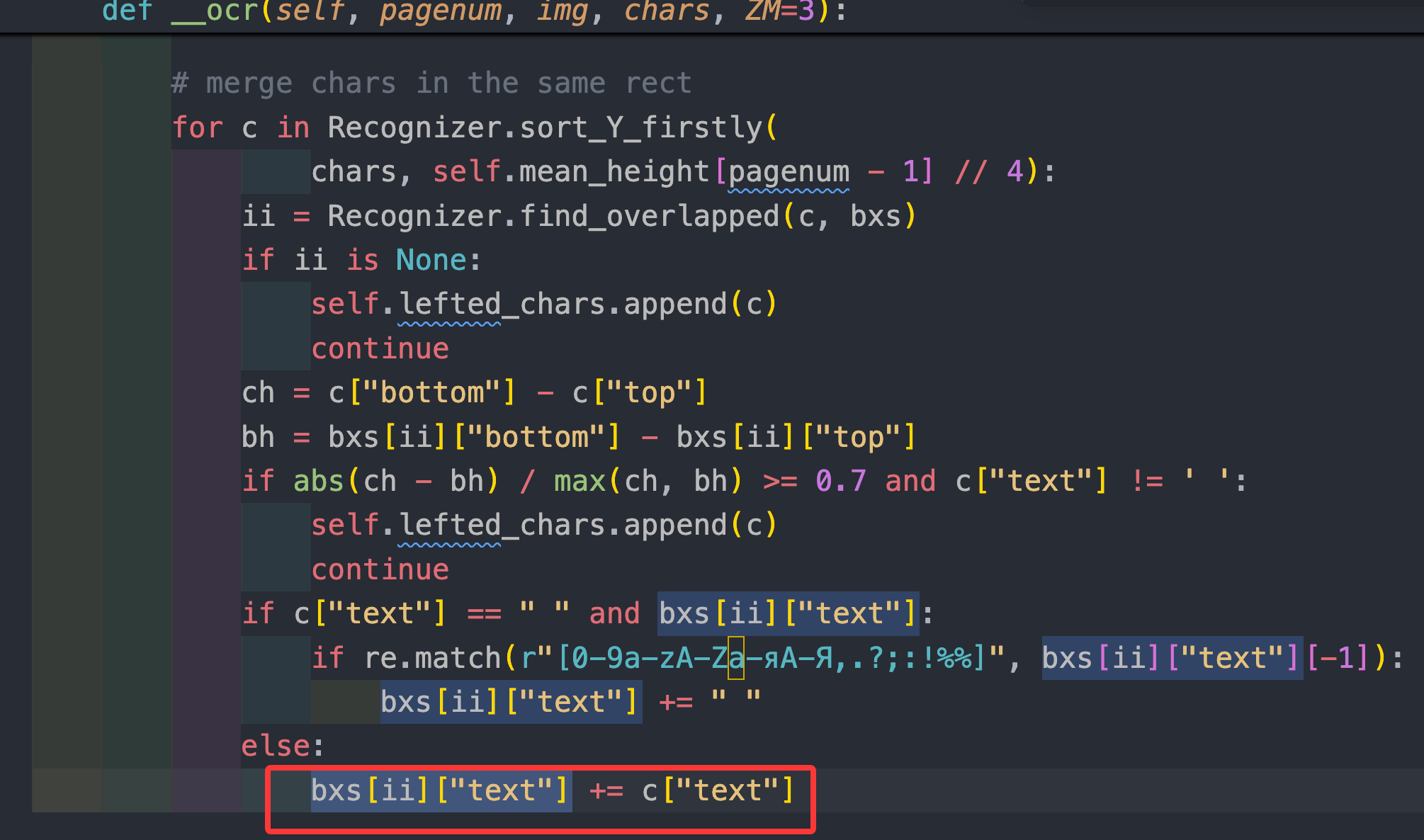
- __ocr() 里把这些字符填回 OCR 检测框:
|
|
- 原架构的设计,是当 text 为空时,采用 OCR 进一步兜底再去获取 text 的
|
|
然而本质问题是: pdfplumber底层依赖 pdfminer.six,导致他对系统字体和PDF内嵌信息要求很高。

所以PDF 里 pdfplumber 能读到 chars,但读出来是乱码,所以 b[“text”] 不为空,代码就不会走 OCR 兜底。结果就是:检测框和坐标是对的,文本是错的。
那么我直接换掉pdfplumber就能解决吗? 答案不是仅仅换掉就能解决的,pdfplumber需要做 pdf 的图片转换。 由此又引发了两个新的问题:
- 为什么需要两套 PDF 读取?
因为 pypdf 和 pdfplumber 都能“读 PDF”,但它们读的层次不一样。
- pypdf 更像“读 PDF 里的文本流”。
一个实用的工程策略是:用 pypdf 做基础的文本提取,用 pdfplumber 做精细的布局和表格解析。两者结合使用,可以取长补短。
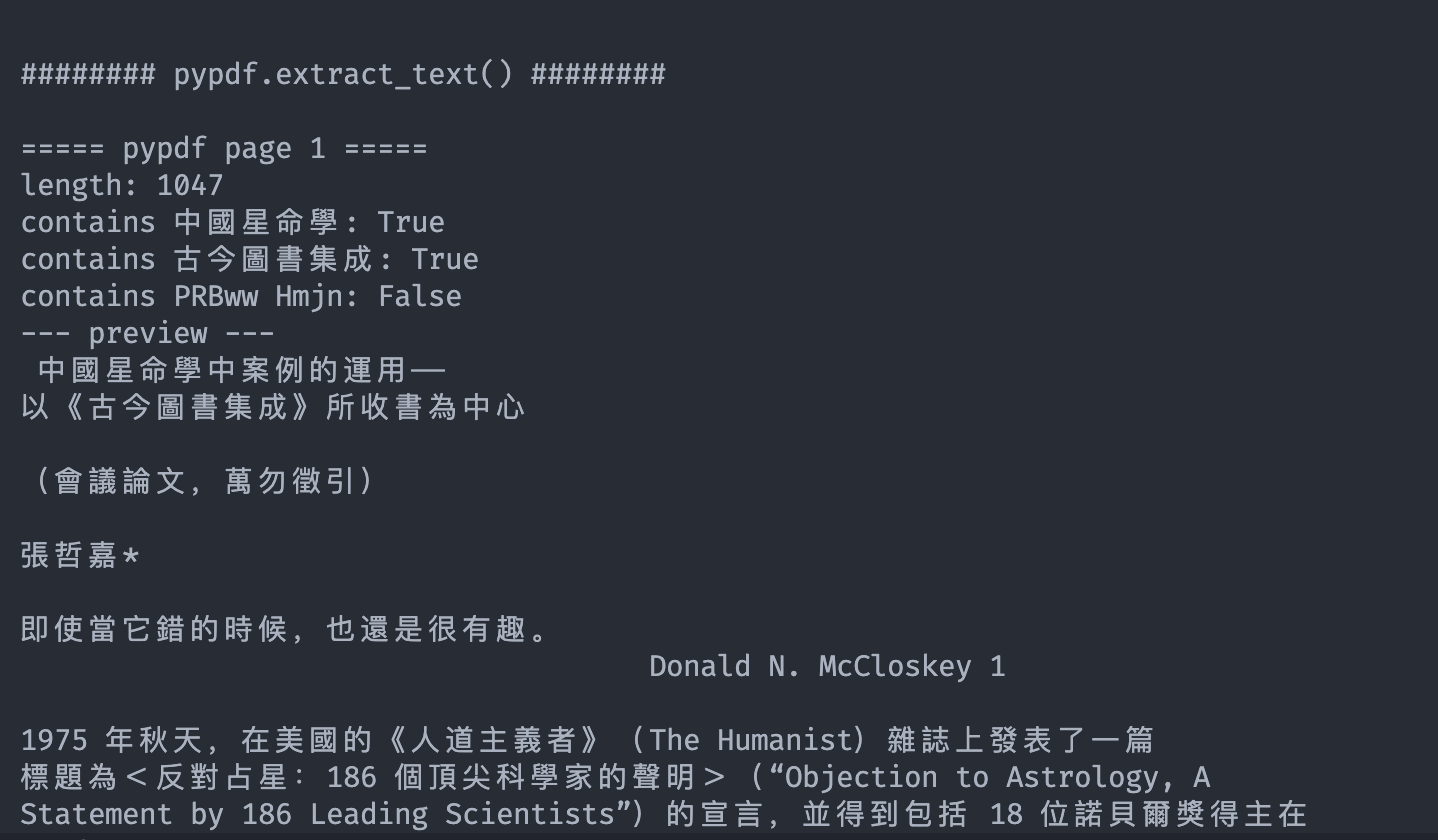
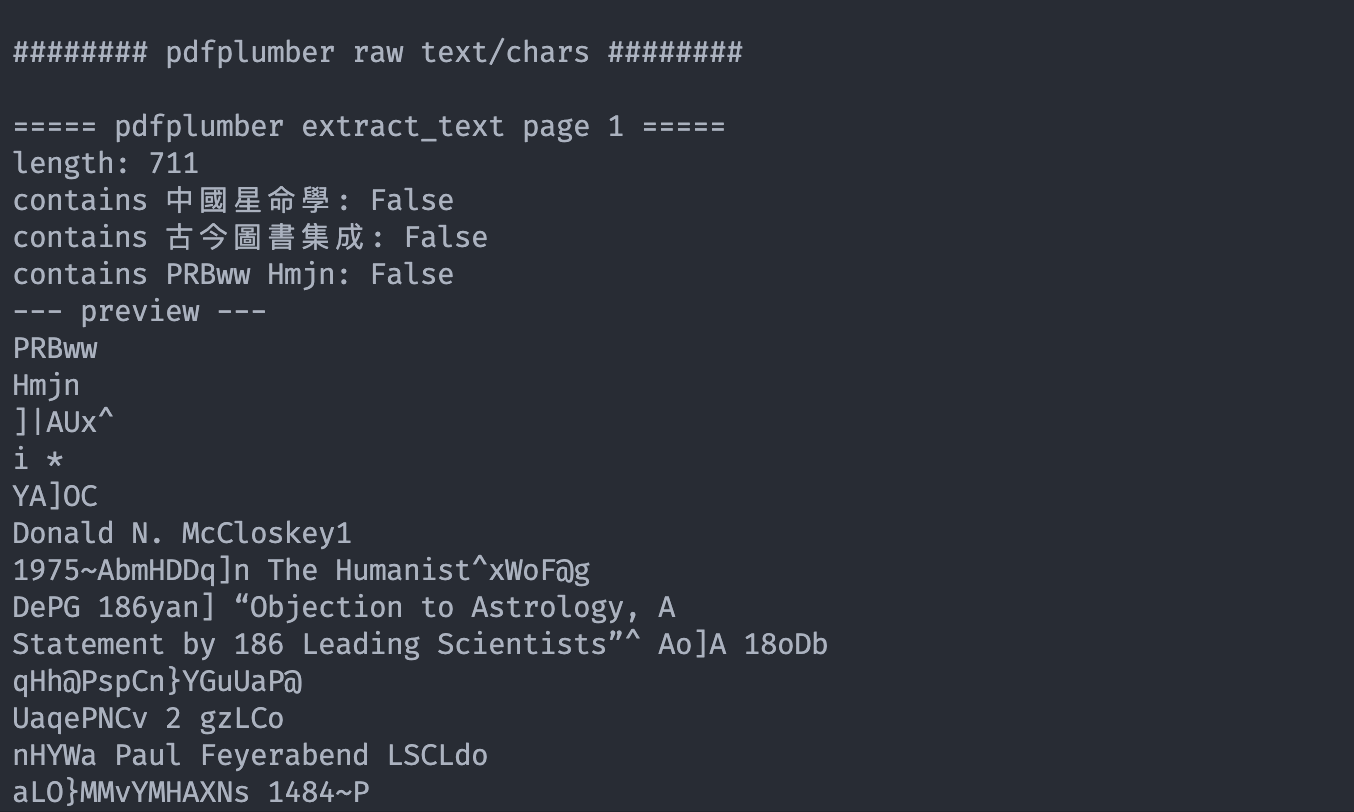
它擅长把 PDF 内部文本抽出来,而且它的底层继承了很多编码格式,较少的依赖系统字体库,pypdf.extract_text() 能读出正常中文。但它基本不给我们稳定的版面坐标、文本框、表格区域、图片区域、阅读顺序结构。
- pdfplumber 更像“读 PDF 的页面版面对象”。 它能拿到字符级坐标、矩形、线条、表格线索、页面位置,所以适合做坐标引用。但 PDF 的中文字体经常使用自定义编码或缺失 ToUnicode 映射,pdfplumber 可能拿到字符位置,却把字符本身解码错,于是出现 PRBww Hmjn 这种乱码。
两者的测试对比:
- 为什么不能直接用现成pdf库读完,还要这么复杂的架构? 因为 RAG 入库不只是要“文本”,还要这些东西:
- 可检索正文
- 页码
- 坐标
- 阅读顺序
- 表格结构
- maybe 扫描版 PDF 的 OCR
- maybe 后续能把答案引用定位回原 PDF 页面区域
如果只用 pypdf,文本可能是对的,但坐标弱,答案引用没法可靠高亮。 如果只用 pdfplumber,坐标强,但遇到这类中文编码 PDF,文本可能是乱码。 如果只用 OCR,坐标和扫描件都能处理,但文本精度、速度、成本都不如直接读取内嵌文本。
所以 pdf_parser.py 的意义是做“生产 RAG PDF 解析器”,不是简单 read_pdf():
|
|
为此,我设计了新的方案处理:
2.1.1 架构优化
- 加页级文本质量判断:
- 提取每页 pdfplumber 文本和 pypdf 文本。
- 判断 pdfplumber 是否乱码:中文比例明显低、ASCII 噪声高、而 pypdf 中文比例明显高时,认为 pdfplumber chars 不可信。
- 对不可信页不再把 pdfplumber chars 传入 __ocr(),强制 解析器重新 OCR 生成检测框和坐标。
- 实现“双路合并”:
- OCR 负责生成文本框、阅读顺序、页码和坐标。
- pypdf 负责提供可信正文行。
- 当 pypdf 行数和 OCR 框数量大致匹配时,按阅读顺序用 pypdf 行替换 OCR 框文本,保留 OCR 框坐标。
- 当行数不匹配时,保留 OCR 框文本,并追加一个带页级坐标 tag 的 pypdf 搜索文本块,保证可检索文本和坐标字段同时存在。
|
|
2.2 页尾内容丢失-页脚处理
这个问题本质是因为: 原架构默认是会剔除页眉页脚,认为这些数据是噪声,会污染 RAG 数据, 所以当pypdf 行数与 OCR 框数不一致,按顺序替换时末行被错绑到页脚或被过滤。 同时经过分析问题 2、3 的过程中发现,是页脚处理的连锁反应导致的,也就是说:
处理之后正确的应该是:
这些问题具有共性:
- 页脚丢失:补充文本如果在 layout 前加入,会被 layout recognizer 清理掉。
- 跨页页高计算错误:在 page_cum_height 尚未累加时用相邻页高差,导致第一页以后正文/页脚拆分失效。
- 右上角引用号问题:无法清楚知道什么是脚注、什么是正文。
2.2.1 架构优化
这部分涉及正文、非正内容区分,我按照分层理论进一步抽象一个 scholarly 层做数据层,原 parser 透传给这一层,处理完后,吐回去。
本节进行稍显简单的记录一下,这个抽象层具体实现,需要单独写一篇文章,我后面会补☝️
 也就是说目前架构:
也就是说目前架构:
|
|
实现逻辑上:
在现有 PDF parser 的“可检索文本 + 坐标”基础上,新增一层结构化引用关系:
-
正文引用号保留为
citation_refs_nst -
页脚脚注来源保留为
footnotes_obj。 -
字段示例: 当前结构是两层:
|
|
所以问题来了:
- 怎么判断是不是小角标? 原来的设想是用正则从正文里面找,试了很多规则和方式,测试都不理想,最后结合几何判断,终于搞定。
|
|
拆解来看的话就是:
-
只看正文区域
1char["top"] < page_height * 0.82页脚里的脚注编号不参与正文引用号判断。
-
计算正文正常字号/行高,数字字号显著小于本页正文中位字号。
1normal_height = median(正文字符高度) -
把相邻数字合并成候选 由
_digit_groups()完成,比如把连续的9、9合成99。 -
排除年份/普通数字
1 2if len(text) > 3: continue比如
1975、1312直接排除。 -
字号必须明显小于正文
1marker_height < normal_height * 0.82 -
附近必须有正文正常字号字符 也就是它不能孤零零出现在页脚、页码或其它区域, 避免把页码、表格数字、年份误判为角标。
-
位置必须上移
1 2raised = neighbor_center - marker_center raised >= normal_height * 0.18这就是“右上角小数字”的关键:它比同一行正文基线更靠上。
最终生成:
|
|
综合下来就是 用 字号 + 坐标 + 行高 + 上移量 判断。
经过这个处理后,拿到了准确的引用角标,就能更好的理解我前文的数据结构,为啥是那样设计的了:
citation_refs_nst是“正文里的角标引用点”列表;footnotes_obj是“页脚里的脚注来源文本”字典。它们靠footnote_key对应。
可以把两者理解成:
|
|
对应关系是:
|
|
例如我拿到一条数据:
|
|
它对应:
|
|
也就是:
|
|
字段含义:
|
|
脚注编号。这里是第 1 号引用。
|
|
正文里看到的角标文本。通常和 ref_id 一样。
|
|
正文角标出现在哪一页。
|
|
正文角标的位置坐标:
|
|
也就是说第 1 页,角标框大概在:
|
|
|
|
表示这个位置是按“上标/小角标字符”识别出来的,不是整行坐标。
|
|
最重要的关联键。格式是:
|
|
所以 "1:1" 就去找:
|
|
|
|
脚注来源在第几页。当前只做同页脚注,所以一般和 page_num_int 一样。
|
|
页脚脚注来源的位置坐标。格式同样是:
|
|
|
|
置信度。现在 0.9 表示它是通过字号、位置、行高判断出来的上标引用号,比纯文本猜测可靠。
完整关系是这样的:
|
|
等价于:
|
|
然后你就能得到:
|
|
所以前端展示时可以这样组织:
|
|
但是如果你爱琢磨的话,那么问题又来了,你为啥要分别用两个数据结构,进行关联,一个数据串起来就够了啊?
💗 恭喜你,发现了本质问题:角标如何和引用正确关联起来呢? 一个自然而然的想法是,找到了脚本,拿着角标去页脚区域匹配,然而很遗憾的是经过实践,这样的话不是很准。 最佳实践是:分两步走,不要关联!!!
- 小角标就去正文找
- 具体的引用内容就去页脚找
- 分别建立两个数据结构,一个关联角标,一个关联引用内容,用页码做主建来关联即可。
2.3 拆分正文和非正文
前面说了一大堆,但是前面的准确与否,都依赖哪个区域是正文,于是准确区分正文、非正文,就摆上了台面,我的实践是抽象_detect_footer_region模块,做隔离层。
而且页脚区域判断不能只用固定 page_height * 0.82,应该综合几何特征:
- 位于页面底部区域。
- 字号/行高明显小于正文。
- 和正文最后一行之间有较大垂直间隔。
- 有些 PDF 页脚上方有横线,可以作为强证据。
- 页码要排除,不能当脚注。
- 如果 layout/OCR 框能区分出底部小字号文本,就优先用框坐标;pypdf 文本只作为内容来源。

这几步有几个关键的步骤,能更快的定位:
1. “和正文最后一行之间有较大垂直间隔”怎么判断
先把页面里的文本框按 top/bottom 排序,然后估算本页正常正文行距:
|
|
然后找疑似页脚第一行和正文最后一行之间的距离:
|
|
如果满足类似条件,就认为它们之间有明显断层:
|
|
也就是说,不是固定说“距离大于多少像素”,而是跟本页自己的正文行距比较。这样不同字号、不同 DPI、不同页面尺寸都能适配。
比如正文正常行间距大概是 12,正文最后一行到底部脚注第一行之间突然有 45,那就是很强的页脚分隔信号。
2. “页脚上方有横线”怎么判断
如果用 pdfplumber,页面里通常能拿到 page.lines 或 page.edges。判断横线大概看这些字段:
|
|
横线特征:
|
|
比如:
|
|
然后再看它和脚注第一行的位置关系:横线必须在页脚文字上方,而且距离不能太远。
|
|
最终用打分决定 footer region
- 不是单个条件命中就算页脚。
- 例如:
- 底部位置 +1
- 小字号/小行高 +1
- 大 gap +1
- 横线 +2
- 脚注编号结构 +1
- 达到阈值才生成
footer_region_int。
同时我会保留一个低置信度 fallback,但它只作为兜底:
|
|
也就是说,主路径会按几何区域判断;固定比例(page_height * 0.82)只在证据不足时兜底,不能再作为主要逻辑。
这个模块具体实现那确实有点复杂,就不一一展示了,不过输入输出的展示,聪明的大家都能完美复刻实现思路的👋🏻:
|
|
输入:提供了当前页面的所有基础布局和文本信息:
-
page_index(整数):- 含义:当前处理的是 PDF 的第几页(从 0 开始计数)。
- 作用:用于在后续提取特定页面的
pypdf_lines或生成区域坐标时作为索引依据。
-
boxes(列表,元素为字典):- 含义:当前页面上的所有文本框(Bounding Box)集合。
- 结构:每个字典代表一个文本框,包含坐标(如
x0,top,bottom等)和文本内容(如text)。
-
chars(列表):- 含义:当前页面上的字符级别信息。
- 作用:辅助计算页面宽度等几何信息。有时文本框的边界不够精确,需要通过字符的极值来框定范围。
-
page_height(浮点数/整数):- 含义:当前页面的总高度(通常以 PDF 点/像素为单位)。
- 作用:作为计算页脚位置的基准。比如算法判断页脚必须出现在页面 62% 高度以下,就需要用到这个总高度。
-
pdf_lines(列表):- 含义:当前页面上的线段信息(如表格线、分隔线)。
- 作用:用于检测主体和页脚之间是否存在“水平分隔线”(
has_rule),这是判断脚注的一个重要特征。
输出是一个包含 7 个键的字典,它将页面上的文本框明确划分为了“主体”和“页脚”两部分,并给出了位置和置信度信息:
-
body_boxes(列表):- 含义:被判定为主体内容的文本框列表。
- 说明:这些是排除了页脚后,页面上剩余的正文文本框。
-
footer_boxes(列表):- 含义:被判定为页脚/脚注内容的文本框列表。
- 说明:如果算法认为没有页脚,该列表为空
[]。
-
body_region_int(对象/整数):- 含义:主体区域的边界范围。
- 说明:由
self._position_from_boxes计算得出,通常是包含所有body_boxes的最大外接矩形(如[x0, y0, x1, y1]),方便后续直接裁剪或定位主体区域。
-
footer_region_int(对象/整数或 None):- 含义:页脚区域的边界范围。
- 说明:和
body_region_int类似,是所有footer_boxes的外接矩形。如果没有检测到页脚,则为None。
-
footer_region_confidence_flt(浮点数):- 含义:页脚检测的置信度分数。
- 说明:范围在
0.0到0.99之间。分数越高,表示算法越确信这部分真的是页脚。如果没检测到页脚,分数为0.0。
-
promoted_footer_lines(列表):- 含义:被“提升”为页脚的文本行。
- 说明:有些文本可能按常规排版不属于页脚,但在语义上属于脚注(比如通过正文的引用关系找到的脚注),
self._promoted_footer_lines会把这些特殊的行单独提取出来。
-
footer_line_positions(列表):- 含义:页脚文本行的位置信息列表。
- 说明:遍历
footer_boxes,通过self._position_from_box计算出每一个页脚文本框的具体坐标位置,通常用于在 PDF 阅读器上高亮显示或做区域遮罩。
虽然这章节看起来比较复杂,但是用我们 codeview 时评语,能更好的领悟:你可以把这个模块想象成一个切蛋糕的机器:
- 输入:一整块蛋糕(
boxes),蛋糕的高(page_height),蛋糕上的装饰线(pdf_lines)等。 - 处理:机器在蛋糕 62% 的高度往下找,看看有没有明显的缝隙或装饰线,判断底部那一小块是不是底座(页脚)。
- 输出:上半部分主体蛋糕(
body_boxes和body_region_int)、下半部分底座(footer_boxes和footer_region_int)、以及机器对“这确实是底座”的把握程度(footer_region_confidence_flt)。
2.4 RAG检索增强-CCH
所谓的CCH就是上下文标题增强:Contextual Chunk Headers。
这是一种为了RAG提高准确性的方法,朴素的标准分块方法经常丢失重要上下文,从而使检索效果降低。
所以通过上下文片段标题(CCH)通过在嵌入每个片段之前为其添加高级上下文(如文档标题或章节标题)来增强RAG,这提高了检索质量并防止了脱离上下文的回复。
也就是说我们的非结构化内容(PDF等等)输入后:
- 如果有目录,最好能提取出来单独用数据结构保存,这样在检索时,能更好的匹配到上下文。
- 如果没有目录,现在都有 LLM 了,可以让 LLM 帮我们做文本摘要生成。
我们运营、策划的知识库还是比较规范的,都处理成了标准带目录的。 在当前架构优化中,使用 pypdf 提取目录outLines,
|
|
最终生成的目录结构如下:
|
|
2.5 倍率转换
通过 把 PDF 页面按 3 倍分辨率渲染成图片,让 OCR / Layout / TSR 模型看得更清楚,同时再用 / zoomin 把模型输出坐标还原回 PDF 坐标。**
|
|
在整个流程处理中,都用到了这个倍率转换:
|
|
为什么默认是 3?
首先这也是一个工程实践的最佳经验值。
- PDF 本身不是图片,vision 模型需要图片输入
在 __images__() 里:
|
|
PDF 默认 72 DPI( 72 磅 = 1 英寸)。zoomin=3 后就是:
|
|
这会把页面渲染得更清楚。
如果不放大,比如 72 DPI,很多小字、表格线、页脚文字,对 OCR 和版面模型来说太糊。
- OCR / Layout / TSR 都在图片坐标系里工作
比如 OCR 检测到了图片上的文字框:
|
|
但原 PDF 坐标应该除以 ZM:
|
|
如果 ZM=3:
|
|
- 表格裁剪和引用截图也依赖这个倍率
裁剪表格时,PDF 坐标要乘回图片坐标:
|
|
生成引用截图时也是类似逻辑:
|
|
所以 zoomin 是两个坐标系统之间的比例尺:
|
|
- 为什么不是 1,也不是越大越好?
zoomin=1:
|
|
zoomin=3:
|
|
zoomin=9:
|
|
如果实在拿不到数据,架构中有放大重试:
|
|
默认先用 3,如果完全没识别到文本框,再尝试 9。
2.6 plain Parser
经过前面的设计,是不是觉得这个 Parser 太复杂了,虽然结果精准了,但随之带来的问题就是慢,所以如果我们上传知识库时,知道有没有复杂的图片、表格、公式等,就可以选择不同的解析器:
-
plain Parser:纯文本解析器,只解析文本框,不解析图片、表格、公式等。
-
full Parser:全解析器,解析文本框、图片、表格、公式等。
-
新增策略层
pdf_parser_strategy.py:- 定义
PdfParserMode = DeepDOC | Plain Text | Auto,统一模式校验和归一化。 - 策略层不加载 OCR/Layout/TSR 模型,只做低成本探测。
- 定义
|
|
这里的检测算法判断逻辑分为两层:
- 小中型 PDF:轻量全量扫描
不是渲染图片,也不是跑 OCR/Layout/TSR,只用 pdfplumber 读取每页的轻量信息:
|
|
如果页数不大,比如:
|
|
那就扫描全部页面。
只要任意一页出现:
|
|
直接返回:DeepDOC
只有所有页面都通过“简单纯文本”检查,才返回Plain Text
- 超大 PDF:分层抽样 + 保守兜底
如果 PDF 很大,比如30页以上,全部 pdfplumber 检查也可能慢。此时不要只看前几页,而是做 分层抽样:
|
|
例如 300 页,可以抽:
|
|
但注意:抽样无法证明后面没有复杂页。
所以默认逻辑是:超大 PDF 如果不能全量轻量检查,默认 DeepDOC.
显式配置:
|
|
只有业务明确接受风险,才允许超大 PDF 通过抽样判断为 PlainParser。
也就是说当前端上传超大 PDF 时,如果选择 Auto,默认会返回:
|
|
Auto 内部:
|
|
算法模块的极简实现:
|
|
- 默认行为保持不变:不传
parser_mode时仍走DeepDOC。 - 前端选择的是“用户意图”,后端仍负责校验、归一化和安全回落。
在不断地踩坑、解决、在踩坑,螺旋递进中,不断感悟一哦个原则:工程优化没有最好,只有适配当前项目需求才行,不要过度设计!!!
文章作者 沐桢